2026 自托管 GLM 5.2 实战:硬件选型、vLLM 部署与成本对照
在 8x H200 上跑 GLM 5.2 FP8、4x H100 跑 Q4 GGUF、Mac Studio 跑 2-bit。753B MIT 权重,1M 上下文,硬件账、云 GPU 时租、Z.ai 月付 $30 三方对照,附 4 个 day-one 推理引擎。
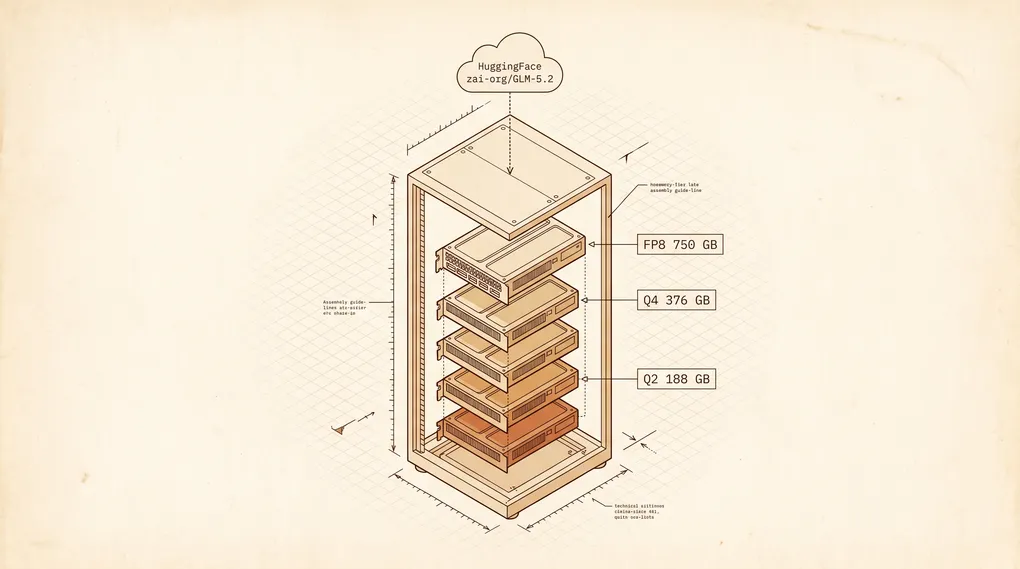
智谱这次发布 GLM 5.2 不只是开了个 API。MIT 许可的权重本周也上了 HuggingFace,这意味着头一回有一款前沿级别、1M 上下文的代码模型,你能真正拉下来、审计、跑在自己机器上。代价是机器本身:753B 参数塞不进你桌下的笔记本。
自托管 GLM 5.2 你能拿到什么(30 秒速答)
| 项 | 内容 |
|---|---|
| 今天就能做的事 | 从 HuggingFace 拉 zai-org/GLM-5.2-FP8,在单台 8x H200 节点用 vllm serve 起服务 |
| 磁盘需求 | FP8 约 750 GB;BF16 约 1.5 TB;Q4_K_M GGUF 约 376 GB;2-bit UD-IQ2_XXS 约 241 GB |
| 最小生产配置 | 8x H200 141GB(FP8)或 4x H100 80GB(Q4_K_M GGUF 走 llama.cpp) |
| 折腾党配置 | Mac Studio M3 Ultra,统一内存 ≥256 GB(M3 Ultra 最高曾可配 512 GB,512 GB 顶配 SKU 已于 2026 年 3 月下架),跑 UD-IQ2_XXS 约 3–9 tokens/秒 |
| Day-one 可用引擎 | vLLM v0.23.0+、SGLang v0.5.13.post1+、Transformers v5.12+(5.x 系列;v5.12.1 于 6 月 15 日发布)、KTransformers v0.6.1+;GGUF 走 llama.cpp;xLLM v0.10.0+ |
| 许可 | MIT — 商用、修改、再分发均允许 |
| 和托管比成本 | 云上 8x H200 节点大约 $30–$50/小时;Z.ai Pro Coding Plan 月费约 $30。自托管的盈亏平衡线在每天 3,000 prompts 以上 |
早期三方证据:第一方 benchmark + Code Arena 前端榜
智谱随发布给了完整的第一方 benchmark 表(见 github.com/zai-org/GLM-5 README)。对自托管决策最有参考价值的几组数字:
| Benchmark | GLM 5.2 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 62.1 | 69.2 | 58.6 |
| Terminal-Bench 2.1 (Terminus-2) | 81.0 | 85.0 | 84.0 |
| Terminal-Bench 2.1 (Best Reported Harness) | 82.7 | 78.9 | 83.4 |
| AIME 2026 | 99.2 | 95.7 | 98.3 |
| GPQA-Diamond | 91.2 | 93.6 | 93.6 |
| MCP-Atlas (Public Set) | 76.8 | 77.8 | 75.3 |
| DeepSWE | 46.2 | 58.0 | 70.0 |
| HLE | 40.5 | 49.8* | 41.4* |
(* = 带工具 / 公开了 harness 变体,详见源表脚注。)SWE-bench Pro 原始分上 GLM 5.2 落后 Opus 4.8(62.1 vs 69.2),但在 Terminal-Bench 2.1 的「Best Reported Harness」一项反超(82.7 vs 78.9),AIME 99.2 vs 95.7 也领先。公开表里缺的几项:SWE-bench Verified、LiveCodeBench、Aider polyglot——开源圈做代码评测最常引用的三套基准,目前都还没给。
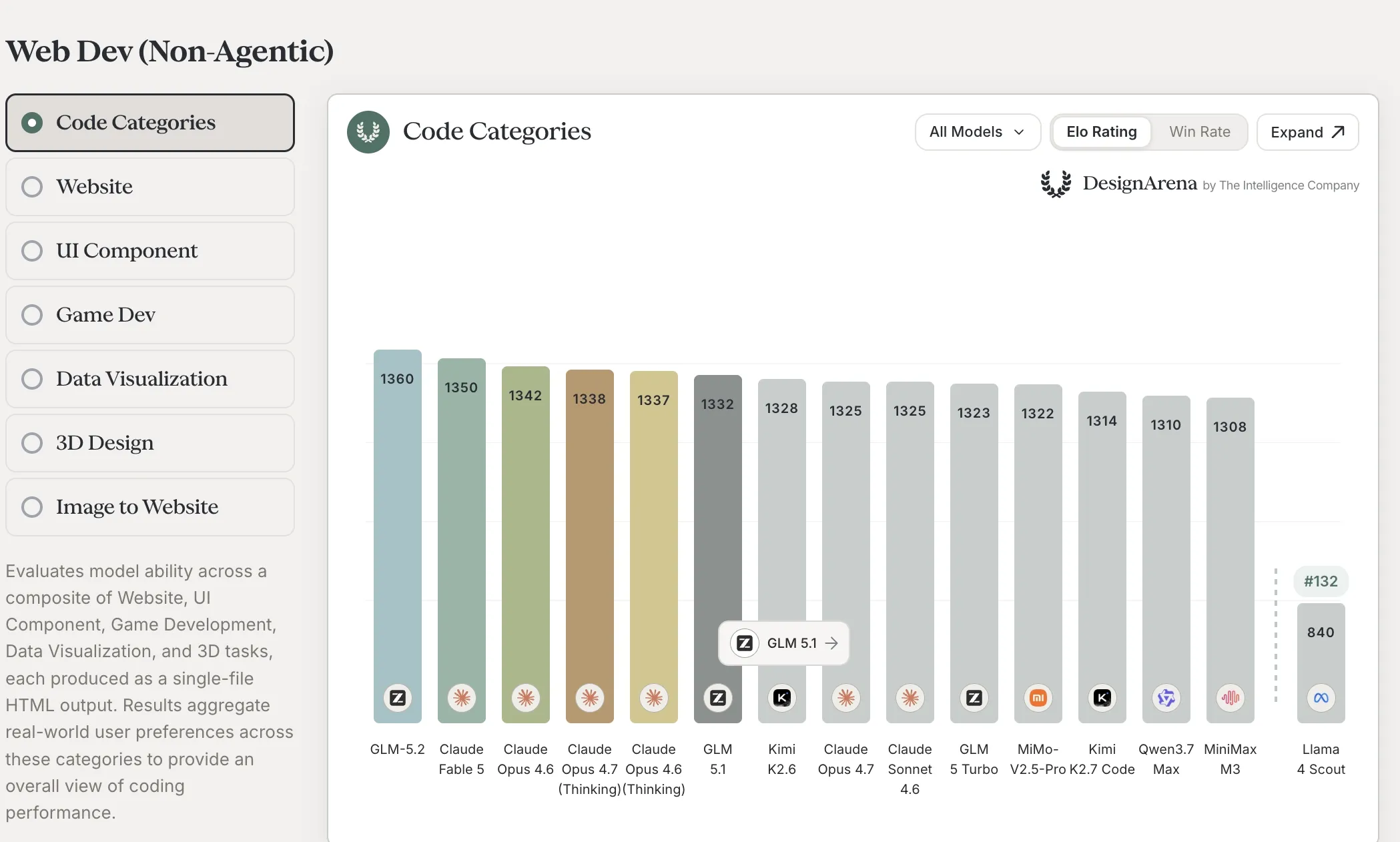
72 小时内,The Intelligence Company 旗下两份独立三方榜也释放了信号。DesignArena 的 Web Dev(Non-Agentic)综合榜上 GLM 5.2 排第 1(Elo 1,360,超过 Claude Fable 5 的 1,350 以及 Claude Opus 4.6 / 4.7 / 4.7-Thinking 全家桶)。在另一域名 Arena Intelligence 上托管的 Code Arena Frontend 分项里它排第 2(Elo 1,595,被 Claude Fable 5 的 1,654 压制——但 Fable 5 在该视图上明确带「not currently being sampled」星号说明)。
![]()
这些证据两种读法:
- 要做自托管决策的人:GLM 5.2 在智谱第一方表里把对 Opus 4.8 的差距追得很近,代码向评测上稳压 GPT-5.5;DesignArena 这份盲偏好 web-dev 综合榜上更是登顶——把所有正在采样的 Claude Opus 都干掉了。和开源圈其他模型的差距,综合榜领先 30–50 Elo(Qwen 3.7 Max 1,310、Kimi K2.6 1,328、GLM 5.1 1,332),前端分项领先 60+ Elo。如果你本来就在评估开源模型上生产代码场景,GLM 5.2 这下把开源圈直接拉开了一档
- 持怀疑态度的人:厂商 benchmark 表就是厂商挑过 harness 的 benchmark 表。DesignArena 测的是 web-dev 输出的两两盲偏好,不是 held-out 测试集上的端到端通过率;前端榜的 Fable 5 星号也提醒你,「排名」会在采样恢复时摆动。两份证据都该当作强领先指标,不能替代在你自己代码库上跑自己的评测
决策框架:什么时候自托管才是答案
这一节用来帮你提前止损,看完不必往下读。
什么时候应该自托管 GLM 5.2
- 数据驻留 — 客户的代码或 prompt 不能离开你的 VPC、所在区域或硬件边界
- 自定义微调 — 你需要在自己代码库上做 LoRA 或全量微调,而托管 API 没暴露这个能力
- 内网隔离部署 — 实验室、工厂、国防或受限网络环境,任何到
api.z.ai的出站流量都是非起手项 - 高持续吞吐 — 每天 ≥3,000 prompts,硬件摊销成本已经低于每请求的云费率
什么时候不要自托管 GLM 5.2
- 你是个人开发者或 2 人小团队。Z.ai Pro Coding Plan 每月约 $30 已经覆盖了你的用量,是跑一台 8x H200 24/7 的 1%。直接看托管接入指南就行
- 你团队还没有跑在生产里的 vLLM 或 SGLang 部署。建立这一摊(驱动生命周期、KV cache 调优、可观测性)的工程成本是真实存在的,至少要一个季度才能回本
- 你特别在意厂商背书的 SWE-bench Verified、LiveCodeBench 或 Aider polyglot 分数。智谱当前公开的是 SWE-bench Pro 62.1、Terminal-Bench 2.1 81.0 / 82.7 best-harness、AIME 2026 99.2、GPQA-Diamond 91.2、MCP-Atlas 76.8 等等(见上表),但开源圈做代码 agentic 对比常用的那三项基准目前都还没给。独立 FP8 精度差也还要等几天才出
止损规则
如果你的峰值负载不到每天 100 prompts,并且没有任何合规约束排除托管方案,不要自托管。买 Coding Plan,省下一个季度的工程投入,等到「应该自托管」四条触发器真正命中再回来看。
Day-one 实际可用的资源
flowchart LR
HF[huggingface.co/zai-org] --> BF16[GLM-5.2 BF16<br/>~1.5 TB]
HF --> FP8[GLM-5.2-FP8<br/>~750 GB]
US[huggingface.co/unsloth] --> GGUF[GLM-5.2-GGUF<br/>Q4 376 GB / Q2 241 GB]
BF16 --> vLLM[vLLM 0.23+]
FP8 --> vLLM
FP8 --> SGLang[SGLang 0.5.13+]
GGUF --> Llama[llama.cpp]
GGUF --> LMS[LM Studio]| 来源 | 仓库 / tag | 格式 | 磁盘 | 适用场景 |
|---|---|---|---|---|
| HF 官方 | zai-org/GLM-5.2 | BF16 | ~1.5 TB | 研究、微调、最高质量生产 |
| HF 官方 | zai-org/GLM-5.2-FP8 | F8_E4M3 | ~750 GB | H100/H200/MI300X 上的生产推理 |
| HF 社区 | unsloth/GLM-5.2-GGUF | GGUF 量化 | 188–376 GB | llama.cpp、LM Studio、单机折腾 |
| Ollama | glm-5.2:cloud | 云端转发 | 不适用 | 仅便利方案 — 不是本地下载 |
关于 Ollama tag 的说明:截至 2026 年 6 月 17 日,ollama.com/library/glm-5.2 上的 glm-5.2:cloud 条目是纯云端(:cloud 后缀走 Ollama 自家托管推理,不是你的机器)。官方 Ollama 库目前没有 glm-5.2:latest 或任何本地量化 tag。如果你确实想要 Ollama 的本地推理体验,用 llama.cpp 加 Unsloth GGUF,外面包一层 Ollama 兼容代理。
另一个值得标记的细节:Unsloth GGUF 仓库在本文发布前几个小时才上线,文章核验时 HuggingFace UI 上还没给每个 quant 文件的具体大小。上面 188–376 GB 的范围是按裸 bit-per-weight 推算的(753B 参数下 2-bit 是 188 GB,4-bit 是 376 GB)。实际磁盘大小因 overhead 可能高 10–20%——下载前请查看「Files and versions」页面的实时数字。
按量化档分硬件选型
正确的档位由权重加载完后剩多少 VRAM 决定。在 1M 上下文场景下,真正悄无声息把你榨干的是 KV cache。
| 档位 | 磁盘 | VRAM 中权重 | 256K 上下文 KV cache | 最小生产配置 |
|---|---|---|---|---|
| BF16 | ~1.5 TB | ~1.5 TB | ~50 GB | 16x H100 80GB(1.28 TB)或 8x H200 141GB(1.13 TB)— H200 紧,可能要 offload |
| FP8 (E4M3) | ~750 GB | ~750 GB | FP8 KV 下 ~25 GB | 8x H200 141GB(1.13 TB)— 舒适;8x H100 80GB(640 GB)— KV cache 受限 |
| Q4_K_M GGUF | 裸权重 ~376 GB(实际文件可能更大) | ~376 GB | ~20 GB | 4x H100 80GB(320 GB)— 紧;2x H200 141GB(282 GB)— 可跑 |
| Q2_K / UD-IQ2_XXS | ~188–241 GB | ~188–241 GB | ~15 GB | 单工作站:≥256 GB DDR5 + 80 GB GPU offload,或统一内存 ≥256 GB 的 Mac Studio M3 Ultra |
套这张表时几条经验:
- VRAM 留 20% 余量给权重加 KV 之外。CUDA 碎片化会吃掉剩下的,你不会想在一个 900K token 请求 prefill 到 90% 时调 OOM
- KV cache 随上下文长度线性增长。表里 256K 的数字只是示意,1M 上下文下 KV footprint 大约是 4 倍。1M 生产负载基本上必须开 FP8 KV cache(vLLM 里加
--kv-cache-dtype fp8) - GGUF 在 llama.cpp 上用的是主机 RAM,不是 VRAM——M3 Ultra 能跑是因为 256 GB UMA 对 CPU 和 GPU 都可见。一台 256 GB DDR5 工作站配 24 GB GPU 也是同样原理,只是慢
vLLM 部署(FP8,8x H200)
绝大多数生产团队会走这条路。vLLM 最低需 v0.23.0,后续 patch 会有吞吐优化,但 GLM 5.2 FP8 这条路径在 0.23 GA 上就能跑。
第 1 步:拉权重
# 约 750 GB;10 GbE 连接下预算 30–60 分钟
huggingface-cli download zai-org/GLM-5.2-FP8 \
--local-dir /models/glm-5.2-fp8 \
--local-dir-use-symlinks False预期结果:/models/glm-5.2-fp8 下有 750 GB 的 safetensors 分片和配置文件。用 du -sh /models/glm-5.2-fp8 核对,并确认目录里有 config.json 和 *.safetensors.index.json。
第 2 步:启动 vLLM server
vllm serve "zai-org/GLM-5.2-FP8" \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--port 8000为什么这样配:
--tensor-parallel-size 8把 753B 权重在 8 块 GPU 上切片。H200 单节点累计 1.13 TB HBM,对 FP8 权重加工作 KV cache 来说留得很宽裕--max-model-len 262144从 256K 上下文起步。把它拉到 1048576(1M)前,先在真实负载上压一遍 KV cache 压力--kv-cache-dtype fp8让 KV cache 占用相比默认 BF16 砍半,是同一并发请求能塞 256K 还是 128K 的分水岭--enable-prefix-caching复用共享 prefix 的 KV——对那些把同一个系统 prompt 调用几百遍的代码 agent,这是基操
预期结果:启动后大约 3–5 分钟,vLLM 会日志输出 Available KV cache memory: X GB 和 Maximum concurrency for Y tokens: Z requests。第一个请求耗时 30–90 秒(compile + KV cache warm-up),之后短 prompt 子秒级返回。
第 3 步:冒烟测试
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "zai-org/GLM-5.2-FP8",
"messages": [{"role":"user","content":"Reply with only the string OK."}],
"max_tokens": 16
}' | jq -r '.choices[0].message.content'预期结果:约 1 秒内返回 OK 或 OK.。如果你拿到的是 500 加 out of memory 或 device-side assert,说明 KV cache 预算配得太紧——把 --max-model-len 降到 131072 再试。
SGLang 部署(FP8,RadixAttention)
SGLang 是另一个生产备选,在 prefix 复用很多的长上下文负载上(多轮代码 agent、稳定 system prompt 的 RAG)通常吞吐更好。
python -m sglang.launch_server \
--model-path zai-org/GLM-5.2-FP8 \
--tp 8 \
--context-length 262144 \
--kv-cache-dtype fp8_e4m3 \
--enable-mixed-chunk \
--port 30000SGLang 的 RadixAttention 在长上下文上是杀手锏——对一个每轮都复用 100K 系统 prompt 的代码 agent,同硬件下你能看到相对 vLLM 0.23 的约 3 倍 requests/秒。代价是工程面稍大(RadixAttention 自己有一套可观测性故事要学)。
llama.cpp / Mac Studio 路线(Q4 或 Q2 GGUF)
折腾、笔记本上做开发、或单机内网隔离部署的场景,llama.cpp 配 Unsloth GGUF 量化是把「GLM 5.2 跑起来」做到最便宜的路径。
# 拉一个 4-bit 量化——把文件名换成实际发布的 Q4_K_M 分片
huggingface-cli download unsloth/GLM-5.2-GGUF \
GLM-5.2-Q4_K_M.gguf \
--local-dir /models/glm-5.2-gguf
# 用 CUDA 编 llama.cpp(Mac 跳过这步,Metal 自动构建)
cmake -B llama.cpp/build -DGGML_CUDA=ON
cmake --build llama.cpp/build --config Release -j
# 起 OpenAI 兼容 API,端口 8080
./llama.cpp/build/bin/llama-server \
--model /models/glm-5.2-gguf/GLM-5.2-Q4_K_M.gguf \
--ctx-size 32768 \
--n-gpu-layers 999 \
--host 0.0.0.0 --port 8080在 256 GB 统一内存的 M3 Ultra Mac Studio 上,2-bit UD-IQ2_XXS 量化大约能跑 3–9 tokens/秒,具体看上下文长度。单人做代码 agent 工作够用,多人共享团队不够。Mac 上把 --ctx-size 降到 16K 能拿到最高的交互式吞吐。
成本:自托管 vs Z.ai Coding Plan
「自托管省钱」这条结论在绝大多数情况下都是错的。按 2026 年 6 月的云价算笔账:
| 场景 | 硬件 | 月成本 | 备注 |
|---|---|---|---|
| 托管(Z.ai Pro Coding Plan) | 无 | 约 $30 | 每周约 2,000 prompts 上限 |
| 托管(Z.ai Max Coding Plan) | 无 | 约 $80 | 每周约 8,000 prompts 上限 |
| 自托管 8x H200(云上,24/7) | 预留实例 | 约 $21k–36k | $30–50/小时综合价 |
| 自托管 8x H200(云上,9–5 按需) | 同硬件,每月 200 小时 | 约 $6k–10k | 多数团队其实跑不到 24/7 |
| 自托管自有 8x H200 | 资本支出 + 电费 | 摊销约 $3k–5k/月 | 约 $20 万硬件按 4 年摊 + 电费 |
| 自托管 256 GB M3 Ultra | 自有工作站 | 摊销约 $50/月 | 一次性约 $8k;电费约 $30/月 |
几个值得记住的盈亏平衡点:
- 托管 Pro vs 自有 M3 Ultra:摊销下,托管月用量超过 $30 时 M3 Ultra 占优——但前提是 3–9 tokens/秒能满足你的工作流
- 托管 Max vs 云上 8x H200:你需要 ≥3,000 prompts/天 并且 H200 节点 ≥30% 的工作时段占用率,云方案才能打过每月 $80 的托管。这相当于一个 20 人开发团队不停跑代码 agent
- 自有 8x H200:每天 ≥10,000 prompts 之上才占优,且前提是你真的有机房承载能力和运维团队。对大多数公司,这意味着 6 个月的采购周期才能跑第一个 prompt
规律就是:95% 的团队应该选托管。自托管赢在那 5% — 合规、数据驻留或持续吞吐需求把价格因素压过去的场景。
自托管常见错误
| 报错 | 可能原因 | 修复 |
|---|---|---|
模型加载时 CUDA out of memory | TP size 太小或 KV cache 预算太宽 | 把 --tensor-parallel-size 调到等于 GPU 数;把 --max-model-len 砍到计划值的一半再逐步加 |
RuntimeError: FP8 ops not supported | GPU 是 Ampere(A100),不是 Hopper(H100/H200) | FP8 E4M3 需要 Hopper 及以上。A100 用户改用 llama.cpp 加 Q4_K_M GGUF |
model has tied_word_embeddings: false 警告 | vLLM 自动检测和 config 不一致 | GLM 5.2 上可以忽略,config 是对的 |
| 500K+ token 请求 504 / 连接重置 | 首 token 时延超过默认客户端超时 | 客户端超时设到 600 秒;vLLM 用 --max-num-seqs 4 降低并发 prefill |
SGLang 首次运行 RadixAttention IndexError | tokenizer 缓存错位 | 删掉 ~/.cache/sglang/ 重启——首次推理会重建缓存 |
GGUF 加载报 tensor not found: blk.X.attn_q.weight | llama.cpp 版本太老,不认 GLM MoE DSA | 把 llama.cpp 升级到 Unsloth GGUF 发布之后的构建,cmake --build llama.cpp/build 重编 |
| 输出和 Z.ai 托管不一致 | 采样参数没对齐 | 按 huggingface.co/zai-org/GLM-5.2/generation_config.json 的官方默认:temperature 1.0、top_p 0.95(top_k 不设);同一 prompt 在两个端点都跑一遍,确认对齐 |
自托管不划算时的备选:ofox 托管路径
如果自托管的账算不过来,但你又想要一个走 OpenAI 兼容端点的中国系代码模型,ofox 当前列了三个 day-one 替代:
| 模型 | ofox model ID | 上下文 | 比自托管 GLM 5.2 更适合的场景 |
|---|---|---|---|
| DeepSeek V4 Pro | deepseek/deepseek-v4-pro | 1M | 你想要 SWE-bench Verified 数字(DeepSeek 有公布;GLM 5.2 公开表只到 SWE-bench Pro),且社区使用记录更长 |
| Kimi K2.6 | moonshotai/kimi-k2.6 | 262K | 你需要被独立 benchmark 过、不是「号称」的长上下文 |
| Qwen 3 Coder Next | bailian/qwen3-coder-next | 256K | 多语言代码库(中文 / 日文 / 韩文的注释和标识符) |
接入形态和自托管端点一样,只换 base URL 和 model ID:
export OPENAI_BASE_URL="https://api.ofox.io/v1"
export OPENAI_API_KEY="ofox-..."
export OPENAI_MODEL="deepseek/deepseek-v4-pro"截至 2026 年 6 月 17 日,ofox 模型库还没上 GLM 5.2。一旦上架,从 deepseek-v4-pro 切到将来的 z-ai/glm-5.2 就是一行字符串的事。今天想走 Z.ai 托管路线,配套的 GLM 5.2 接入指南详细讲了 Z.ai Coding Plan 端点形态、API 密钥,以及给 Claude Code 用户走的官方 Anthropic 兼容端点。
第一天就该上的可观测性
自托管 GLM 5.2 生产环境,有三个信号必须接:
- Tokens/秒承载下,p50 / p95 分开跟踪。一个 900K 上下文请求能把 p99 拖拽一个数量级
- KV cache 使用率 — vLLM 在
/metrics上暴露vllm:gpu_cache_usage_perc,持续超过 90% 时吞吐会塌 - 单请求总 token 数 — 代码 agent 会在兔子洞 refactor 里疯狂烧 token;在 PR 或 session 级别埋点,遇到失控循环能在它把预算吃光之前发现
把这些信号接到你已经在跑的栈(Datadog、Honeycomb、Grafana 都行——挑一个,别再起第四个)。SGLang 对应的 metrics 在 /metrics_collect。
参考信息来源
- HuggingFace 官方 model card — https://huggingface.co/zai-org/GLM-5.2
- HuggingFace FP8 model card — https://huggingface.co/zai-org/GLM-5.2-FP8
- 智谱 GLM-5 GitHub README — https://github.com/zai-org/GLM-5
- DesignArena 榜单 — https://www.designarena.ai/leaderboard
- Arena Intelligence Code Arena Frontend — https://arena.ai/leaderboard/code
- Ollama 库页面 — https://ollama.com/library/glm-5.2
- Unsloth GGUF 社区量化 — https://huggingface.co/unsloth/GLM-5.2-GGUF
- ofox 模型库 — https://ofox.io/en/models
- 配套 ofox 接入指南 — https://ofox.io/zh/blog/glm-5-2-access-guide-2026/
- Reddit r/LocalLLaMA 讨论帖 — https://www.reddit.com/r/LocalLLaMA/comments/1u7o9vp/glm_52_api_is_live_weights_are_on_hf_and_ollama/
- PyPI 版本索引 — https://pypi.org/project/transformers/
这次发布最有意思的不是 1M 上下文,也不是 FP8 版——而是第一次有一款带真正代码血统的开源前沿模型,能塞进中等规模研究机构的采购预算里。接下来 90 天的看点是社区能不能把 FP4 量化做出来,把生产配置从 8x H200 砍到 4x H100。一旦发生,自托管的账就翻盘了。


