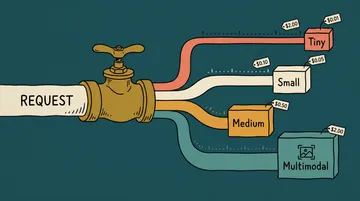
Kimi K2.7 Code:砍掉 30% token 真能让账单变便宜吗?(2026)
Kimi K2.7 Code 每 token 价格和 K2.6 一样($0.95/$4.00)。它砍掉 30% 思考 token,能让推理重的账单省约 13%,输入重的不到 1%。

TL;DR。 Kimi K2.7 Code 每 token 价格和 K2.6 一模一样($0.95/M 输入,$4.00/M 输出),缓存读取还略差一点($0.19/M 对 $0.16/M)。所以账单要变低,全押在 Moonshot 那句「思考 token 少烧约 30%」上。只有当推理主导你的开销时,这削减才是真金白银。推理重的任务账单降约 13%,不是 30。输入重的任务降幅 不到 1%。纯文本推理的活选 K2.7 Code(moonshotai/kimi-k2.7-code),要图片或输出短的活留在 K2.6(moonshotai/kimi-k2.6)。撑起这波热度的 benchmark 全是厂商自报、未经验证,所以唯一值得信的数字,是你自己的账单。
TL;DR:你该选哪个?
一句话结论:如果你的 coding 流量是纯文本、推理重,K2.7 Code 能省下实打实的钱;其余场景里,那个「砍 30%」基本上等流到发票上时就蒸发掉了。
坑在于把「少 30% token」读成「便宜 30%」。它不是。每 token 价格一样、上下文窗口一样、缓存还稍微差点。省钱只活在一个地方,而你得先够格。
| 你的工作负载 | 选 | 原因 |
|---|---|---|
| 纯文本、推理重的 coding(长思考轨迹) | K2.7 Code | 思考 token 占你输出开销的大头,30% 削减落得很重 |
| agentic 循环、长时间自主运行 | K2.7 Code | 推理 token 的减少在多轮中累积 |
| 视觉 / 截图 / 图片输入 | K2.6 | K2.7 Code 只支持文本;image_url block 会失败 |
| 输入重、输出短(RAG、摘要、分类) | K2.6 | 输出只占账单一丝,输出砍 30% 总账省不到 1% |
| 在重复上下文上大量复用缓存 | K2.6 | K2.7 Code 缓存读取 $0.19/M 对 K2.6 的 $0.16/M,缓存输入上 K2.6 更便宜 |
| 你还没量过自己的思考/输出比例 | 先测 | 整个决策都系在这个比例上;下面 10 行的 A/B 循环直接给你 |
如果你只记住一件事,请认真对待最后一行。本文里每一个金额都取决于你输出 token 里走推理的占比,而这个数字只属于你的流量。厂商 benchmark 不会告诉你,你自己的日志会。
规格速览对比
按 2026 年 6 月 26 日 ofox 模型目录核对。价格按每百万 token 计。
| 规格 | Kimi K2.7 Code | Kimi K2.6 |
|---|---|---|
| ofox model ID | moonshotai/kimi-k2.7-code | moonshotai/kimi-k2.6 |
| 上下文窗口 | 262,144 | 262,144 |
| 最大输出 | 262,144 | 262,144 |
| 输入 $/M | $0.95 | $0.95 |
| 输出 $/M | $4.00 | $4.00 |
| 缓存读取 $/M | $0.19 | $0.16 |
| 模态 | 仅文本 | 文本 + 图片 |
| 架构 | 1T MoE / 32B 激活 | MoE |
| 自带思考 | 是 | 是(思考 / 非思考模式) |
| 发布 | 2026-06-12 | 2026-04-21 |
| 许可 | Modified MIT(开放权重) | 开放权重 |
下面所有结论都由三个事实决定:
- 每 token 价格相同。 两者都是输入 $0.95、输出 $4.00。你要是已经给 K2.6 算过价,就等于给 K2.7 Code 的每 token 单价算过了。
- 缓存读取在 K2.7 Code 上更差。 $0.19/M 对 $0.16/M。如果你的流水线大量复用缓存上下文,在这一项上 K2.7 Code 是更贵的那个。差不多,但它跟「更便宜」的说法是反着来的。
- K2.7 Code 只支持文本。 大家最容易漏的细节:ofox 上的 Code 变体不收图片,K2.6 收。另有一个
moonshotai/kimi-k2.7-code-highspeed变体,同价,仍然只支持文本。
价格持平加上更差的缓存费率,意味着能让你账单下降的杠杆有且只有一个,就是思考 token 的削减。本文剩下的内容都在说:这根杠杆动不动得了你这张具体发票。
Coding benchmark:Moonshot 报了什么(哪些没经验证)
Moonshot 发布时给出的 K2.7 Code 对 K2.6 的数字看着很猛。列在下面,每一行都带着同一句注脚。
| Benchmark | K2.6 | K2.7 Code | 报告涨幅 | 第三方验证过? |
|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | +21.8% | 否 |
| Program Bench | 48.3 | 53.6 | +11.0% | 否 |
| MLS Bench Lite | 26.7 | 35.1 | +31.5% | 否 |
最后一列读两遍。三个全是 Moonshot 自家的专有 benchmark。没有独立复现,截至 6 月 12 日发布,也没有 SWE-bench Verified、LiveCodeBench 或 GPQA 上的公开结果——而那才是业界真正拿来互相比较的几把尺子。
VentureBeat 报道这次发布时用的标题,正是说从业者认为这些 benchmark 对不上。研究者 Elliot Arledge 在公开的 GPU-kernel benchmark KernelBench-Hard 上把 K2.7 Code 和 K2.6 对跑,结果它的 MoE-kernel 得分从 K2.6 的 0.222 退步到 0.157,调优更差。所以从 Moonshot 之外看,这画面往好了说是参差,往差了说,至少在一个公开测试上指向了反方向。
除了「这是第一方数据」,还有个结构性理由要打折看这些数字。一个分数分布很窄的厂商 benchmark,可以在很小的绝对位移上做出很大的百分比涨幅;一个专有测试框架,无论有意无意,都可能被调到向随它一起发布的那个模型倾斜。真正能为路由决策定调的 benchmark,是那种模型间分布很宽、方法学公开的,真实能力差距会以巨大的分差体现出来。K2.7 Code 发布时没被送进那类测试。所以你拿到三个亮眼的百分比,却没法把它们摆在你可能改去路由的那些模型旁边比。
这对成本工作尤其要紧。如果你切去 K2.7 Code 有一部分是指望它输出质量更好(更少重试、更少纠错轮次),厂商 benchmark 不是你能下注的证据。更少重试确实是真实的成本节省——每次失败的尝试都是你付过钱的 token——但你不能靠 Moonshot 之外没人复现过的数字去主张这份节省。诚实的立场是:在你自己的 eval 给出不同结论前,把 K2.7 Code 的质量当作大致和 K2.6 同档,切换的理由就建立在 token 算账上,而不是 benchmark 差值上。K2.6 那条至少公开更久的基线数字,见 Kimi K2.6 发布指南 和 Kimi K2.6 vs Claude Opus 4.6 coding benchmark。
token 算账:30% 究竟落在哪
这里是市场宣传跳过的部分。30% 削减作用于思考/推理 token,而思考 token 按输出(completion)token 计费。你的输入 token 一动不动。
所以一张 Kimi 账单的结构是:
bill = input_tokens × $0.95/M + output_tokens × $4.00/M
where output_tokens = thinking_tokens + visible_tokensK2.7 Code 的削减只砍 thinking_tokens 这一块,砍约 30%。其余原地不动。这给出真实节省的一个干净公式:
bill reduction ≈ 0.30 × (thinking spend / total spend)如果思考是你的全部账单,你能拿到接近 30%。如果思考只占一丝,你拿到的也只有一丝。决定结果的变量,是你花在推理上的开销占比,它从接近全部(agentic、多步 coding)一直跨到接近零(长输入、一行答案)。
Moonshot 自己的说法用一个 agentic 例子讲得很具体:一次 12 小时的运行,推理 token 从约 2M 降到约 1.4M,就是那个 30%。那是厂商示例,不是在你流量上的实测,但它给出了形状——推理 token 主导的工作,正是这削减设计来奏效的地方。
错误在于把那次 12 小时 agent 运行套到每一个任务上。一个读 200K token、写 200 token 的摘要调用是完全相反的画像,它几乎什么都看不到。下一节给两端都标上具体金额。
你不必猜你的思考开销占比——API 会告诉你。每条响应都带一个 usage 对象,里面有 prompt_tokens 和 completion_tokens。思考 token 被并进了 completion token,所以你要的占比是 completion_tokens × $4.00/M 除以整张账单。在一个有代表性的真实流量周里把它记下来,你就能在改动任何一个模型字符串之前,知道自己落在 1% 到 26% 区间的哪一点。决定切换值不值的,是那个实测比例,不是 Moonshot 的示例。
价格算账:真实月度账单
两个推算示例,全部按 $0.95/$4.00 重算。不假设缓存命中,以便孤立出思考 token 的效应。你可以自己重算一遍,算式刻意保持简单。
示例 1:推理重的 coding 任务
画像:50,000 输入 token,20,000 输出 token,其中 70%(14,000)是思考、30%(6,000)是可见答案。这是 agentic coding 的形状:规划、推理、修订。
| 行 | K2.6 | K2.7 Code |
|---|---|---|
| 输入(50,000 × $0.95/M) | $0.0475 | $0.0475 |
| 思考 token | 14,000 | 9,800(−30%) |
| 可见 token | 6,000 | 6,000 |
| 输出 token 合计 | 20,000 | 15,800 |
| 输出成本(× $4.00/M) | $0.0800 | $0.0632 |
| 每任务合计 | $0.1275 | $0.1107 |
账单降幅:($0.1275 − $0.1107) / $0.1275 = 13.2%。
注意发生了什么。思考 token 降了 30%(14,000 → 9,800)。但输出总 token 只降了 21%(20,000 → 15,800),因为可见答案没缩。而账单只降了 13.2%,因为输入 token——这里占成本三分之一——一点没动。「30%」的标题到了发票上变成了 13%。这正好对上公式:0.30 × (思考开销 $0.0560 / 总额 $0.1275)= 13.2%。
放大到真实工作量,每天 1,000 个这种任务,跑 30 天:
| 模型 | 月账单 |
|---|---|
| K2.6 | $3,825.00 |
| K2.7 Code | $3,321.00 |
| 节省 | $504.00/月(−13.2%) |
每月 $504 值得拿。只是别按「$3,825 打三折」那种天真算法去预期 $1,147。
示例 2:输入重的任务(削减几乎看不见)
画像:200,000 输入 token,4,000 输出 token,其中 40%(1,600)是思考。这是 RAG、长文档问答或摘要:大读、短写。
| 行 | K2.6 | K2.7 Code |
|---|---|---|
| 输入(200,000 × $0.95/M) | $0.1900 | $0.1900 |
| 输出 token 合计 | 4,000 | 3,520(思考 1,600 → 1,120) |
| 输出成本(× $4.00/M) | $0.0160 | $0.0141 |
| 每任务合计 | $0.2060 | $0.2041 |
账单降幅:($0.2060 − $0.2041) / $0.2060 = 0.93%。
不到一个百分点。输出对比输入只是个舍入误差,所以砍掉输出的一部分 30%,在发票上看不出来。对这种负载画像,为省钱切去 K2.7 Code 没意义;而如果你靠缓存输入,K2.6 更便宜的缓存读取($0.16 对 $0.19)直接让它成了更便宜的那个模型。
示例 3:12 小时 agentic 运行(上限那端)
Moonshot 的招牌示例是一次 12 小时 agentic 运行,推理 token 从约 2M 降到约 1.4M。那是他们的数字、不是我的,但值得算一下,因为这是最接近 30% 标题的画像。假设这次运行整段生命周期还读了约 500K 输入、产出约 200K 可见输出(工具调用、文件编辑、最终摘要)。
| 行 | K2.6 | K2.7 Code |
|---|---|---|
| 输入(500,000 × $0.95/M) | $0.475 | $0.475 |
| 推理 token | 2,000,000 | 1,400,000(−30%) |
| 可见输出 | 200,000 | 200,000 |
| 输出成本(× $4.00/M) | $8.800 | $6.400 |
| 每次运行合计 | $9.275 | $6.875 |
账单降幅:($9.275 − $6.875) / $9.275 = 25.9%。
这已经是最好的情况。推理在这里压倒性地占账单大头,所以削减几乎全额传导。即便如此也是 26%,不是 30%,因为输入和可见输出没动。每天跑 20 次、跑一个月,差距是真实的:
| 模型 | 月账单(每天 20 次 × 30 天) |
|---|---|
| K2.6 | $5,565 |
| K2.7 Code | $4,125 |
| 节省 | $1,440/月(−25.9%) |
如果你的流量确实长得像长时间自主 agent 运行,K2.7 Code 配得上它的开销。你的负载越往示例 2 那个画像漂,它能做的就越少。
这三个示例框住了真实世界。你的账单降幅落在 约 1% 到约 26% 之间,取决于流量推理有多重,而一个典型的混合 coding 工作负载大致落在 13% 中段。你的输出越接近全是思考,就越靠近标题数字;你的账单越靠输入,省得越少。如果你想干脆把这些不同形状的任务整体路由到更便宜的模型上,那是另一根杠杆,见 一个 API 路由多个模型。
缓存这一项对 K2.7 Code 不利
「便宜 30%」的故事还忽略了一个数字:缓存读取。K2.7 Code 缓存输入按 $0.19/M 计;K2.6 按 $0.16/M。也就是每个缓存 token 都贵 19%——而且偏偏在那个本该更便宜的模型上。
只要你复用上下文,这就有影响。在同一个仓库上反复的代码评审循环、重发系统 prompt 和代码库的多轮 agent 会话、在稳定语料上做 RAG,这些大部分输入都命中缓存。取一个 300K 输入、80% 缓存命中的任务,两个模型输出保持相等以孤立缓存效应:
| 行 | K2.6 | K2.7 Code |
|---|---|---|
| 新鲜输入(60,000 × $0.95/M) | $0.0570 | $0.0570 |
| 缓存输入(240,000) | × $0.16/M = $0.0384 | × $0.19/M = $0.0456 |
| 输入成本 | $0.0954 | $0.1026 |
光输入这一项,K2.7 Code 每任务就多花 $0.0072。每天 1,000 个缓存重的任务、跑一个月,那是约 $216/月 的额外开销,得让思考 token 的节省先填平它你才能打平。在一个缓存读取很重、推理输出很轻的任务画像上(示例 2 的形状再加上缓存),K2.7 Code 可能反而成了更贵的模型。在你假设「越新越便宜」之前,对照一下你自己的缓存命中率。
什么时候选 K2.7 Code
下面几条全成立时选 moonshotai/kimi-k2.7-code:
- 你的活是纯文本。链路里没有图片。
- 你的任务推理重,意思是思考轨迹相对可见答案很长。agentic coding、多步调试、重规划任务。
- 你没有重度依赖缓存复用(如果有,K2.7 Code 的 $0.19/M 缓存读取比 K2.6 的 $0.16/M 更贵)。
这是 30% 思考 token 削减能转化成两位数账单降幅的画像。对这种形状的活,它是实打实的赢。想在同价下要更高吞吐就用 moonshotai/kimi-k2.7-code-highspeed;token 算账不变。
什么时候留在 K2.6
下面任一条成立时留在 moonshotai/kimi-k2.6:
- 你需要图片输入。K2.7 Code 做不了,没得商量。
- 你的任务是输入重、输出短。省下来的钱约等于零(示例 2),而更便宜的缓存读取让 K2.6 成了更低的账单。
- 你依赖非思考模式做快速、直接的回答。如果你压根不产生思考 token,那 30% 削减就没东西可砍。
- 你已经在生产里验证过 K2.6 的质量,又没有实测理由相信 K2.7 Code 做得更好——因为支撑那个的 benchmark 没经验证。
K2.6 是稳妥的默认。除了推理 token 节食这一项,K2.7 Code 会的它都会,外加它收图片、缓存还更便宜。K2.6 的定价和接入细节,见 Kimi K2.5 API 定价与接入指南,它沿用了同样的每 token 结构。
什么时候两个都不该用(以及用什么替代)
两个 Kimi 模型都停在 $0.95/$4.00。那是中段,不是便宜。如果你的核心约束是每 token 裸成本,而任务又不需要 Kimi 级别的推理,两个都不是对的答案。
- 预算型、高吞吐的批处理(分类、抽取、批量摘要),路由到更便宜的档位。DeepSeek V4 Flash 标价 $0.14/$0.28,混合下来大约比 Kimi 便宜 6 倍。见 DeepSeek V4 发布指南。
- 硬推理且你想要另一个模型家族的强项,GLM-5.2 是 ofox 上推理档的替代。见 GLM-5.2 接入指南。
- 上述全混在一起的流量?别只挑一个模型。把每一类任务路由到能过它质量门槛的最便宜模型;这在成本上胜过任何单模型选择。多模型路由实操 里有算好的路由表。
K2.7 Code 的意义是在推理重的文本上拿到一个狭窄的效率收益。如果那不是你的瓶颈,把优化精力花在路由上,而不是这一次单模型替换上。一支在批量分类活上付着 Kimi $4.00/M 输出费的团队,桌上漏掉的钱远比 K2.7 Code 能还回来的那 13% 多,因为那里正确的修法是干脆换个更便宜的模型,而不是换一个昂贵模型的瘦身版。先把模型档位对上任务,再在档位内优化。
用 ofox 把两个都试一遍:10 行做 A/B
上面每一个数字都取决于你自己的思考对输出比例,而你可以直接测出来。两个模型共享一个 OpenAI 兼容 endpoint 和一把 ofox key,所以 A/B 就是在两个模型字符串上跑个循环。把你真实的 prompt 喂给两边,记下 API 返回的 token 数,按你的流量算账单,而不是信一个估算。
Python,一个循环里 A/B 两个模型
from openai import OpenAI
client = OpenAI(base_url="https://api.ofox.ai/v1", api_key="YOUR_OFOX_KEY")
prompt = "Refactor this 200-line module into composable functions: <paste code>"
for model in ["moonshotai/kimi-k2.6", "moonshotai/kimi-k2.7-code"]:
r = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
)
u = r.usage
bill = u.prompt_tokens * 0.95e-6 + u.completion_tokens * 4.00e-6
print(f"{model}: in={u.prompt_tokens} out={u.completion_tokens} bill=${bill:.4f}")Node,同样的形状
import OpenAI from "openai";
const client = new OpenAI({ baseURL: "https://api.ofox.ai/v1", apiKey: process.env.OFOX_KEY });
const prompt = "Refactor this 200-line module into composable functions: <paste code>";
for (const model of ["moonshotai/kimi-k2.6", "moonshotai/kimi-k2.7-code"]) {
const r = await client.chat.completions.create({
model,
messages: [{ role: "user", content: prompt }],
});
const u = r.usage;
const bill = u.prompt_tokens * 0.95e-6 + u.completion_tokens * 4.0e-6;
console.log(`${model}: in=${u.prompt_tokens} out=${u.completion_tokens} bill=$${bill.toFixed(4)}`);
}切换就一个字符串。在你最常用的 20 个真实 prompt 上跑这循环,把账单加总,你就拿到了自己实际的降幅,而不是宣传册上的。
一个坑:K2.7 Code 只支持文本
K2.6 收图片,K2.7 Code 不收。同一个在 moonshotai/kimi-k2.6 上能用的 image_url content block,在 moonshotai/kimi-k2.7-code 上会失败:
# Works on K2.6, fails on K2.7 Code (text-only)
client.chat.completions.create(
model="moonshotai/kimi-k2.6", # swap to kimi-k2.7-code -> error
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "What's in this screenshot?"},
{"type": "image_url", "image_url": {"url": "data:image/png;base64,<...>"}},
],
}],
)如果你 A/B 集合里有任务带图片,让它留在 K2.6,根本别路由到 K2.7 Code。
FAQ
Kimi K2.7 Code 比 K2.6 便宜吗? 不便宜。每 token 价格完全一样($0.95/M 输入,$4.00/M 输出)。缓存读取在 K2.7 Code 上更贵($0.19/M 对 $0.16/M)。通往更低账单的唯一路径是约 30% 的思考 token 削减,且只在推理重的活上。
砍掉 30% token 是不是意味着账单便宜 30%? 不是。削减作用于按输出计费的思考 token;输入 token 不变。实际降幅大约是 30% 乘以你的思考开销占比。推理重的任务约 13%,输入重的任务不到 1%。
Kimi K2.7 Code 在 ofox 上的 model ID 是什么?
endpoint https://api.ofox.ai/v1 上是 moonshotai/kimi-k2.7-code。还有同价的 moonshotai/kimi-k2.7-code-highspeed。K2.6 是 moonshotai/kimi-k2.6。
Kimi K2.7 Code 接受图片吗?
不接受。K2.7 Code 变体只支持文本到文本;image_url block 会失败。视觉任务路由到收文本加图片的 moonshotai/kimi-k2.6。
Kimi K2.7 Code 的 benchmark 数字经过验证了吗? 没有独立验证。+21.8% / +11.0% / +31.5% 的涨幅全是 Moonshot 的专有 benchmark,没有第三方复现。VentureBeat 报道有从业者说这些 benchmark 对不上,一次公开的 KernelBench-Hard 跑测显示出退步。把它们当作厂商自报口径。
Kimi K2.7 Code 的上下文窗口是多少? 上下文和最大输出都是 262,144 tokens(256K),和 K2.6 一样。它是 1T 总参数 / 32B 激活的 MoE,自带思考,2026 年 6 月 12 日以 Modified MIT 开放权重许可发布。
什么时候该从 K2.6 切到 K2.7 Code? 当你的活是纯文本、推理重的 coding,思考主导输出开销时。留在 K2.6 的情况是需要图片输入,或者输入重、输出短的任务——那种省下来约等于零。
有更快的版本吗?
有,moonshotai/kimi-k2.7-code-highspeed,同样 $0.95/$4.00 定价,吞吐更高。它不改变这里的 token 算账。
本次更新核对过的信息源
- ofox 模型页,Kimi K2.7 Code:https://ofox.io/models/moonshotai/kimi-k2.7-code (2026 年 6 月 26 日核对返回 200)
- ofox 模型页,Kimi K2.6:https://ofox.io/models/moonshotai/kimi-k2.6 (2026 年 6 月 26 日核对返回 200)
- Moonshot AI,Kimi K2.7 Code 概览:https://www.kimi.com/resources/kimi-k2-7-code (2026 年 6 月 26 日核对返回 200)
- Hugging Face model card,moonshotai/Kimi-K2.7-Code:https://huggingface.co/moonshotai/Kimi-K2.7-Code (2026 年 6 月 26 日核对返回 200)
- VentureBeat 关于 K2.7 Code 砍 30% 思考 token、以及从业者质疑 benchmark 对不上的报道:https://venturebeat.com/technology/kimi-k2-7-code-cuts-thinking-tokens-30-practitioners-say-benchmarks-dont-check-out (文章确认在线;主机对自动化 curl 返回 bot 验证挑战)
- Elliot Arledge,独立 KernelBench-Hard 跑测(K2.7 Code MoE-kernel 0.157 对 K2.6 0.222):https://x.com/elliotarledge/status/2065443474560946615 ,公开榜单见 https://kernelbench.com/hard (两者 2026 年 6 月 26 日核对返回 200)