AI API 报错完全指南:429/401/500 错误排查与解决方案(2026)
系统梳理 OpenAI GPT-5.4、Claude、Gemini API 常见错误码,覆盖 429 限流、401 鉴权、500 崩溃、超时及 invalid user_id 等问题。附指数退避重试代码、配额升级策略与多模型 Fallback 架构,90% 的 429 错误可彻底解决。

摘要
调 AI API 遇到报错是家常便饭——429 限流、401 鉴权失败、500 服务端炸了,每个都能让你卡半天。本文系统梳理了 OpenAI GPT-5.4、Anthropic Claude、Google Gemini 三大主流 AI API 的常见错误码,给出可复制的排查步骤和生产级代码方案。重点:90% 的 429 错误可以用指数退避 + 请求队列彻底解决,剩下 10% 是额度问题。如果你在用 Cursor、Claude Code 等 AI 编程工具或者搭建 AI Agent,本文的错误处理方案同样适用。
问题背景:为什么 AI API 报错这么多?
如果你用过 OpenAI、Claude 或 Gemini 的 API,大概率遇到过各种报错。不是 429 限流就是 500 崩溃,偶尔还来个 401 让你怀疑人生。2026 年 3 月,随着 GPT-5.4 和 Gemini 3.1 Flash-Lite 的发布,API 生态更加丰富,但报错类型也随之增多。
这不是你的问题。AI API 的报错率天然比传统 API 高,原因有三:
- 资源密集:每次请求都要占用 GPU 算力,服务端对并发极其敏感
- 多级限流:RPM(每分钟请求数)、TPM(每分钟 Token 数)、RPD(每日请求数)三重限制叠加
- 服务不稳定:大模型推理服务的可用性通常在 99.5%-99.9%,比传统 API 的 99.99% 低一个数量级
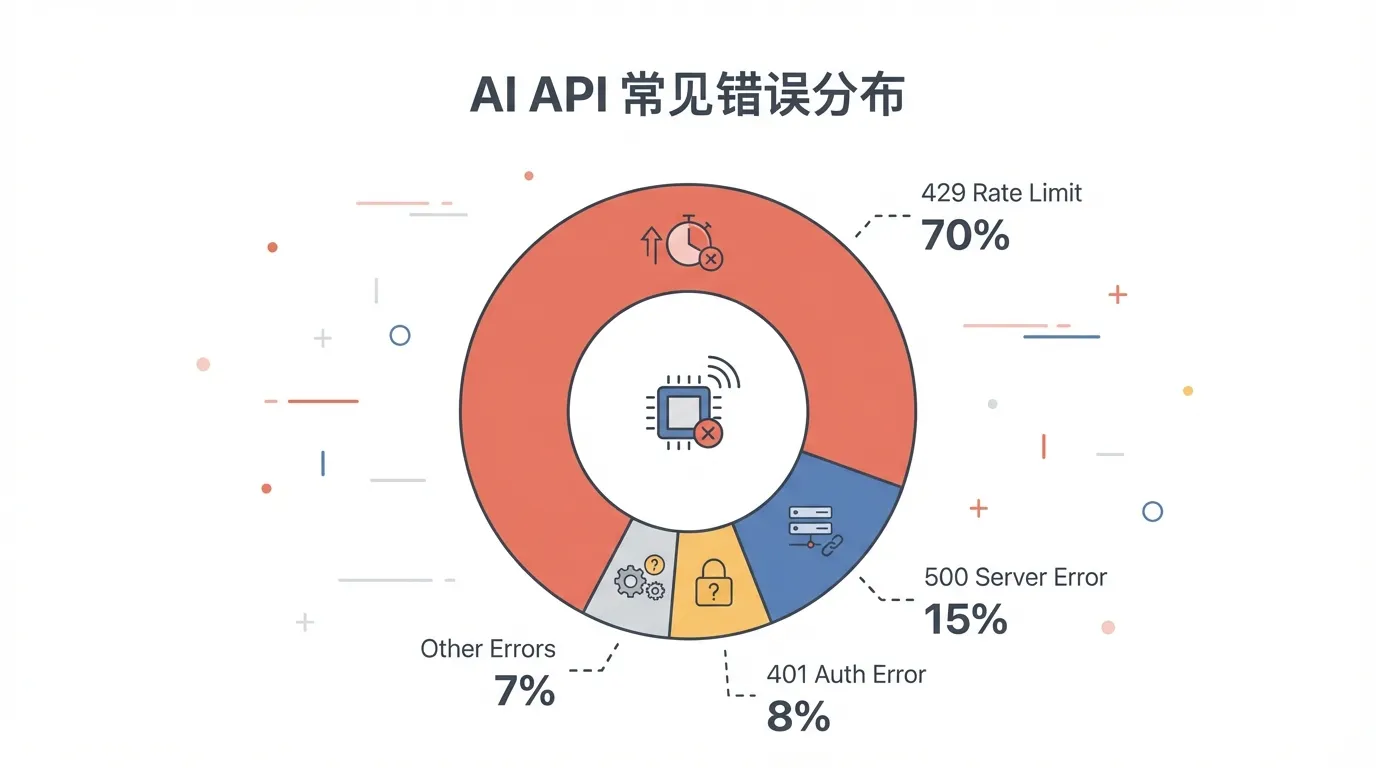
根据社区统计,AI API 报错中 429 限流占 70%,500 系列服务端错误占 15%,认证问题占 8%,其余 7% 是参数错误。
下面按出现频率从高到低,逐一拆解。
429 Too Many Requests:限流错误排查
429 是 AI API 开发者的”老朋友”了,意味着你的请求频率超过了平台限制。
为什么会触发 429?
| 触发原因 | 说明 | 常见场景 |
|---|---|---|
| RPM 超限 | 每分钟请求次数超出配额 | 批量调用、并发测试 |
| TPM 超限 | 每分钟 Token 消耗超出配额 | 长文本处理、大量上下文 |
| 日配额用尽 | 当天请求总量达到上限 | 免费层级用户 |
| 账户余额不足 | 预付费额度用完 | 忘记充值 |
| 组织级限流 | 同一组织下多个项目共享配额 | 团队协作场景 |
排查三步走
第一步:确认是哪种限流
OpenAI 的 429 响应体会告诉你具体原因:
{
"error": {
"message": "Rate limit reached for gpt-4o on tokens per min (TPM): Limit 30000, Used 28000, Requested 5000.",
"type": "tokens",
"code": "rate_limit_exceeded"
}
}关键看 type 字段——tokens 是 TPM 超限,requests 是 RPM 超限。同时注意 429 响应的 Retry-After 头,它会告诉你需要等待多少秒才能发起下一次请求。
第二步:检查当前配额
各平台查看配额的方式:
- OpenAI:platform.openai.com/account/limits
- Anthropic:console.anthropic.com/settings/limits
- Google:aistudio.google.com/apikey
第三步:对症下药
方案一:指数退避重试(必备)
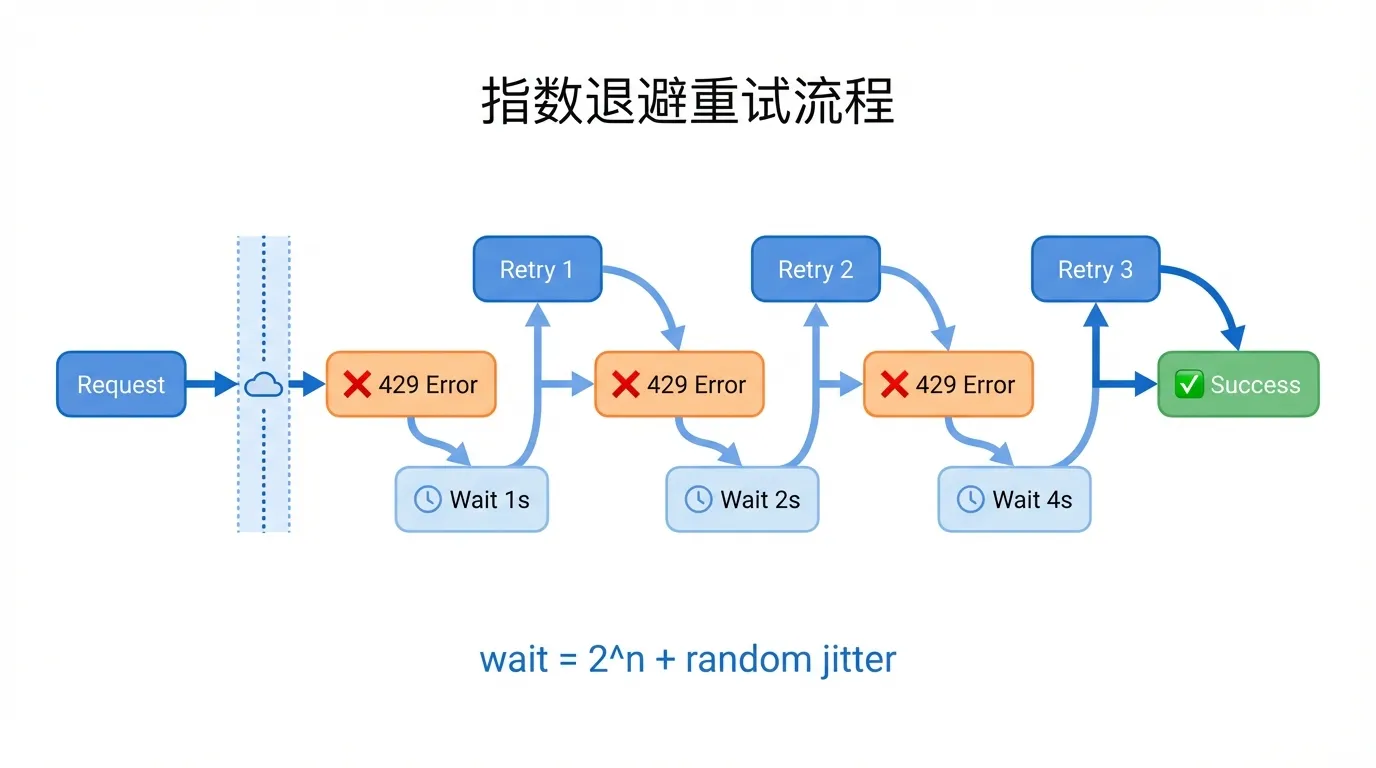
这是处理 429 的标准做法,任何生产环境都必须实现:
import time
import random
from openai import OpenAI
client = OpenAI()
def call_with_retry(messages, max_retries=5):
"""指数退避重试,处理 429 限流"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gpt-4o",
messages=messages
)
return response
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# 指数退避 + 随机抖动
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"限流了,等待 {wait:.1f}s 后重试(第 {attempt+1} 次)")
time.sleep(wait)
else:
raise方案二:请求队列 + 令牌桶限速
当你需要批量处理时,主动限速比被动重试更优雅:
import asyncio
from asyncio import Semaphore
class RateLimiter:
"""令牌桶限速器"""
def __init__(self, rpm=50, tpm=40000):
self.rpm_semaphore = Semaphore(rpm)
self.tpm_limit = tpm
self.tpm_used = 0
async def acquire(self, estimated_tokens=500):
await self.rpm_semaphore.acquire()
while self.tpm_used + estimated_tokens > self.tpm_limit:
await asyncio.sleep(1)
self.tpm_used += estimated_tokens
def release(self):
self.rpm_semaphore.release()
# TPM 每分钟重置(简化实现)
limiter = RateLimiter(rpm=50, tpm=40000)
async def rate_limited_call(messages):
await limiter.acquire()
try:
response = await aclient.chat.completions.create(
model="gpt-4o",
messages=messages
)
return response
finally:
limiter.release()方案三:升级 Usage Tier
如果业务量确实需要更高配额,最直接的方式是升级:
| OpenAI Tier | 月消费门槛 | GPT-4o RPM | GPT-4o TPM |
|---|---|---|---|
| Free | $0 | 3 | 40,000 |
| Tier 1 | $5 | 500 | 30,000 |
| Tier 2 | $50 | 5,000 | 450,000 |
| Tier 3 | $100 | 5,000 | 800,000 |
| Tier 4 | $250 | 10,000 | 2,000,000 |
| Tier 5 | $1,000 | 10,000 | 30,000,000 |
方案四:多模型负载均衡
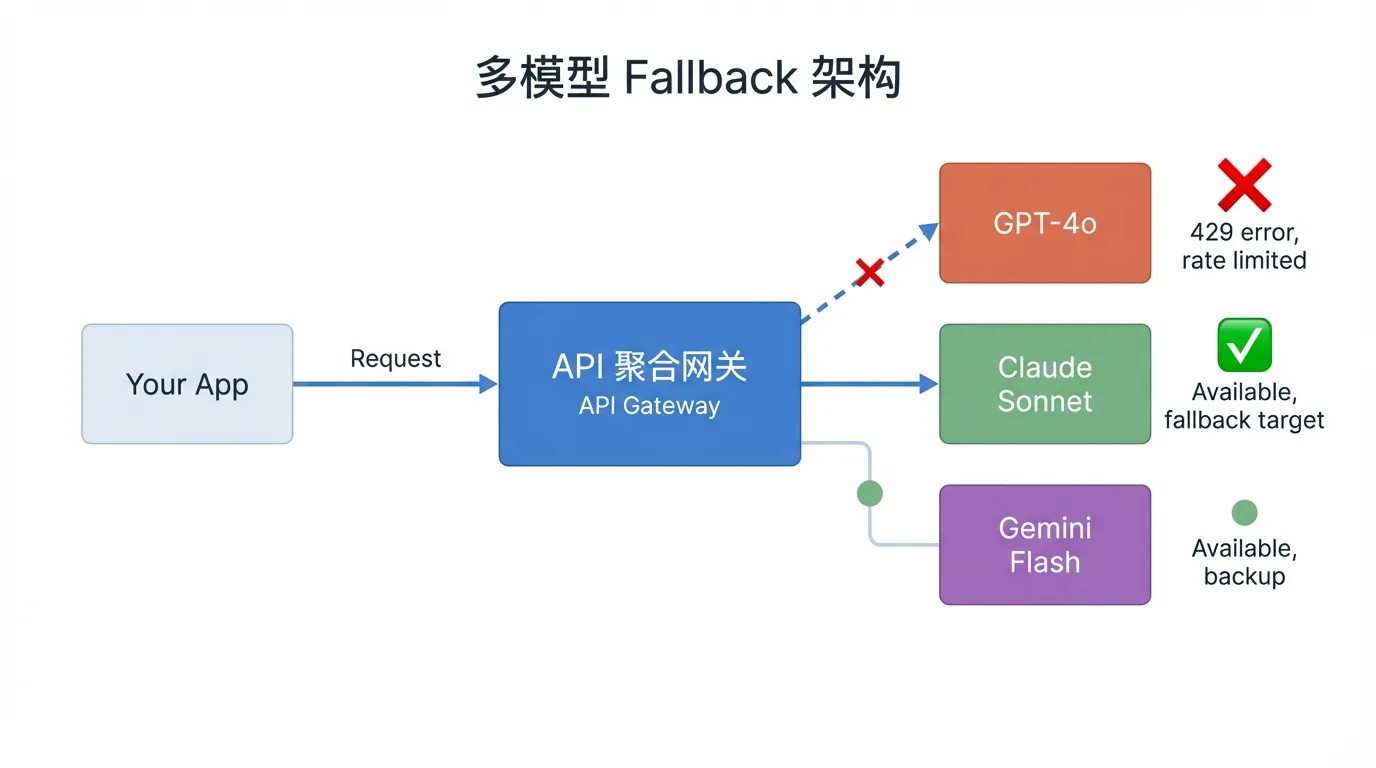
当单一 API 的配额不够用时,可以通过聚合多个模型来分散压力:
from openai import OpenAI
# 兼容 OpenAI SDK,切换 base_url 即可
client = OpenAI(
api_key="your-ofox-key",
base_url="https://api.ofox.ai/v1"
)
# 主模型限流时自动 fallback 到备选模型
models = ["openai/gpt-5.4", "anthropic/claude-sonnet-4.6", "google/gemini-2.5-flash"]
def call_with_fallback(messages):
for model in models:
try:
return client.chat.completions.create(
model=model,
messages=messages
)
except Exception as e:
if "429" in str(e):
continue
raise
raise Exception("所有模型都限流了")通过 API 聚合网关(如 Ofox),可以用统一接口管理多个模型的 fallback 逻辑。
401/403 认证与权限错误
401 Unauthorized
最常见的原因就三个:
- API Key 写错了:复制时多了空格、少了字符
- Key 被吊销:泄露到 GitHub 后被平台自动禁用
- Key 过期:部分平台的 Key 有有效期
快速排查:
# 测试 OpenAI Key 是否有效
curl https://api.openai.com/v1/models \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-s | head -20
# 测试 Anthropic Key
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "content-type: application/json" \
-H "anthropic-version: 2023-06-01" \
-d '{"model":"claude-sonnet-4","max_tokens":10,"messages":[{"role":"user","content":"hi"}]}' \
-s | head -20403 Forbidden
403 和 401 的区别:401 是”你是谁?“,403 是”我知道你是谁,但你没权限”。
常见原因:
- 模型访问权限不足:比如 GPT-4 需要 Tier 1 以上
- 区域限制:部分模型不对某些地区开放
- 组织权限:Key 所属的组织没有开通对应服务
解决方案:检查 API Key 对应的组织权限设置,确认模型访问列表。如果你在使用 Claude API,可以参考 Claude API 国内使用指南 了解完整的权限配置流程。
400 请求参数错误
400 错误意味着你的请求格式有问题。常见的坑:
JSON 格式问题
# ❌ 错误:messages 格式不对
response = client.chat.completions.create(
model="gpt-4o",
messages="请帮我写代码" # 应该是列表
)
# ✅ 正确
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "请帮我写代码"}]
)模型名称错误
# ❌ 这些都会报 400
model = "gpt4o" # 少了横杠
model = "gpt-4-o" # 多了横杠
model = "claude-3.5" # 版本号格式错
# ✅ 正确的模型名称(2026 年 3 月最新)
model = "gpt-4o"
model = "gpt-5.4" # 2026.3 最新
model = "claude-sonnet-4"
model = "gemini-2.5-flash"
model = "gemini-3.1-flash-lite" # 2026.3 最新模型名拼错只是模型特定报错的一种。Claude 的 prefill 限制、OpenAI 的 Tier 权限、DeepSeek 的 402 余额、Gemini 的 QUOTA_EXCEEDED——这些都是通用错误码查不到答案的坑,详见《Claude/OpenAI/Gemini/DeepSeek 模型特定报错排查手册》。
invalid ‘user_id’ 字段错误(OpenAI / DeepSeek / Claude Code)
如果你切换到第三方 base_url 后,请求返回类似下面的 400 错误,说明客户端给 messages 数组塞了 OpenAI / Anthropic 官方 schema 不认的字段:
api error: 400 invalid 'user_id': string above maximum length 64
api error: 400 invalid 'user_id': expected a string
api error: 400 invalid value: 'user_id' is not allowed in messages根因:OpenAI Chat Completions API 的 messages 字段只允许 role、content、name、tool_calls、tool_call_id、refusal 这几个 key,不允许 user_id。但 Claude Code、Codex CLI、各类 wrapper 在本地记录会话时,有时会把内部追踪用的 user_id / session_id 透传到 messages 里。OpenAI 直连不严格校验,第三方网关一旦严格校验立刻 400。
三种客户端的规避方法:
| 客户端 | 触发场景 | 解决 |
|---|---|---|
| Claude Code | 切到 GPT/DeepSeek 第三方 base_url 后,长会话突然报错 | 升级到最新版本(已修复 sanitize 逻辑);或 claude -c 重开会话清空脏 messages |
| Codex CLI | 自定义 model 后 /resume 老会话报错 | 删 ~/.codex/sessions/ 下对应 sessionId 的 JSON 文件,重开 |
| OpenAI SDK 自己写代码 | 混了第三方 wrapper 后串字段 | 调用前过滤 messages,只保留 OpenAI 官方 schema 允许的 key |
用 ofox.ai 中转的额外保护:ofox 网关在转发前会自动 sanitize messages,把所有非标准 key(包括 user_id、session_id、metadata 等)剥离掉再转给上游,本质上让客户端 bug 也跑通。如果你遇到这个错误又改不了客户端代码,切到 ofox base_url 立刻能跑。
Token 超限
每个模型有最大上下文长度限制。当你的 input + max_tokens 超过限制时会报 400:
| 模型 | 最大上下文 | 最大输出 |
|---|---|---|
| GPT-4o | 128K | 16K |
| GPT-5.4 Thinking | 1M | 32K |
| Claude Sonnet 4 | 200K | 64K |
| Gemini 2.5 Flash | 1M | 65K |
| Gemini 3.1 Flash-Lite | 1M | 65K |
解决方法:在发送前估算 Token 数,必要时截断上下文。
500/502/503 服务端错误
服务端错误不是你的问题,但你得优雅地处理它。
500 Internal Server Error
服务端内部错误,通常是临时的。处理策略:
import time
def handle_server_error(func, max_retries=3):
"""服务端错误重试(不退避太久,因为不是限流)"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
error_code = getattr(e, 'status_code', 0)
if error_code in (500, 502, 503) and attempt < max_retries - 1:
time.sleep(2 * (attempt + 1)) # 线性退避
continue
raise502 Bad Gateway
通常是上游服务器过载。在高峰期(如 GPT 新版本发布后)特别常见。
503 Service Unavailable
模型正在维护或过载。Anthropic Claude 在高负载时会返回 529 Overloaded(非标准状态码),处理方式等同 503。Claude 的 429/529/401 等错误码的详细排查见《Claude API 报错汇总》。
实用技巧:关注各平台的状态页:
- OpenAI:status.openai.com
- Anthropic:status.anthropic.com
- Google AI:status.cloud.google.com
408/504 超时错误:API 调用太慢怎么办
AI API 调用慢是开发者最头疼的问题之一。一次 GPT-4o 请求平均耗时 3-8 秒,复杂任务可能超过 30 秒。
延迟优化六板斧
1. 开启 Streaming(最有效)
Streaming 不会减少总生成时间,但能把首字节响应时间(TTFT)压缩到 1 秒以内:
stream = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "写一段代码"}],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")2. 控制输出长度
每个 output token 增加几毫秒到几十毫秒的延迟。明确限制输出长度:
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
max_tokens=500, # 限制输出
temperature=0 # 确定性输出,略微减少延迟
)3. 用小模型替代大模型
不是所有任务都需要最强模型:
| 场景 | 推荐模型 | 平均延迟 |
|---|---|---|
| 简单分类/提取 | GPT-4o-mini / Gemini 3.1 Flash-Lite | <1s |
| 代码生成 | Claude Sonnet 4 / GPT-4o | 2-5s |
| 复杂推理 | GPT-5.4 Thinking / Claude Opus 4 | 5-15s |
4. 精简 Prompt
减少 input tokens 直接降低处理时间。去掉冗余的 system prompt,用结构化指令替代长篇描述。
5. 并行请求
如果有多个独立的 AI 任务,不要串行执行:
import asyncio
async def parallel_calls(prompts):
tasks = [
aclient.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": p}]
)
for p in prompts
]
return await asyncio.gather(*tasks)6. 就近接入
API 请求的网络延迟在中国区尤其明显。直连 OpenAI 的网络往返时间(RTT)通常在 300-500ms,而通过国内云加速节点可以降到 50-100ms。对 streaming 场景效果尤其明显——每个 chunk 都少 200ms 的等待。
AI 编程工具客户端连接错误
这一节专门收 Claude Code、Codex CLI、Cursor 这类本地客户端会遇到的、和服务端 HTTP 状态码无关的错误。它们通常发生在登录、首次连接或代理切换时。
Claude Code:failed to start login: typeerror: fetch failed
执行 /login 或 claude 首次启动时报:
failed to start login: TypeError: fetch failed
at node:internal/deps/undici/undici:13502:13
...
[cause]: ConnectTimeoutError: Connect Timeout Error原因:Claude Code 用 Node 内置 undici 直连 https://console.anthropic.com/v1/oauth/...,国内网络 + 公司代理 + IPv6 三个因素任一都会触发 Connect Timeout。
排查顺序:
- 测网络:
curl -v https://console.anthropic.com,卡住或 timeout 就是网络问题 - 关 IPv6:
export NODE_OPTIONS="--dns-result-order=ipv4first"后重试 - 设代理:
export HTTPS_PROXY=http://127.0.0.1:7890(按你的代理端口改) - 换中转 base_url 跳过 OAuth:彻底绕过 console.anthropic.com 的登录流程
最后一招最快——把 ANTHROPIC_BASE_URL 指到 ofox.ai 中转,ANTHROPIC_AUTH_TOKEN 填 ofox 的 sk-... key,整个 OAuth 登录流程不用走,配完 3 秒可用。
Cursor / Wrapper:invalid chat.send params: missing 'sessionid'
某些把 Claude / Anthropic 协议包装成 OpenAI 协议给 Cursor 用的第三方 wrapper,会要求 messages 数组里附带 sessionid 字段。如果切换 base_url 后报这个错,说明你之前用的 wrapper 实现是非标准的——OpenAI / Anthropic 官方协议里都没有这个字段。
解决:换一个标准 OpenAI 兼容实现的中转。OfoxAI 完全按 OpenAI Chat Completions 标准走,不需要任何额外字段,配置见《Cursor + Claude Code + Cline 接 ofox API 教程》。
客户端错误统一排查 checklist
遇到本地工具报错,按这个顺序排:
- 看错误类型:HTTP 状态码 → 看本文上半部分;JS/Python 异常 → 这一节
- 测一次
curl https://你的-base_url/v1/models:能拿到模型列表说明网络和鉴权都 OK,错在客户端 - 重新登录 / 重开会话:80% 的 sanitize 类问题靠重启会话解决
- 升级客户端版本:Claude Code、Codex CLI 这类工具频繁修 bug,老版本撞坑概率高
- 换中转 base_url:兜底方案,标准实现的中转能屏蔽大部分客户端 bug
生产环境最佳实践:一劳永逸的错误处理
把上面所有方案整合成一个生产级的 API 客户端:
import time
import random
import logging
from openai import OpenAI
logger = logging.getLogger(__name__)
class RobustAIClient:
"""生产级 AI API 客户端,内置错误处理"""
def __init__(self, api_key, base_url="https://api.openai.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
def chat(self, messages, model="gpt-4o", max_retries=5, **kwargs):
for attempt in range(max_retries):
try:
return self.client.chat.completions.create(
model=model,
messages=messages,
**kwargs
)
except Exception as e:
status = getattr(e, 'status_code', 0)
error_msg = str(e)
# 429 限流:指数退避
if status == 429 or "429" in error_msg:
wait = min(2 ** attempt + random.uniform(0, 1), 60)
logger.warning(f"限流,等待 {wait:.1f}s(第{attempt+1}次)")
time.sleep(wait)
continue
# 500/502/503 服务端错误:短暂重试
if status in (500, 502, 503, 529):
wait = 2 * (attempt + 1)
logger.warning(f"服务端错误 {status},等待 {wait}s")
time.sleep(wait)
continue
# 400/401/403 客户端错误:不重试,直接抛出
if 400 <= status < 500:
logger.error(f"客户端错误 {status}: {error_msg}")
raise
# 未知错误
if attempt == max_retries - 1:
raise
time.sleep(1)
raise Exception(f"重试 {max_retries} 次后仍然失败")
# 使用示例
client = RobustAIClient(
api_key="your-key",
base_url="https://api.ofox.ai/v1"
)
response = client.chat(
messages=[{"role": "user", "content": "Hello"}],
model="openai/gpt-4o"
)各平台错误码速查表
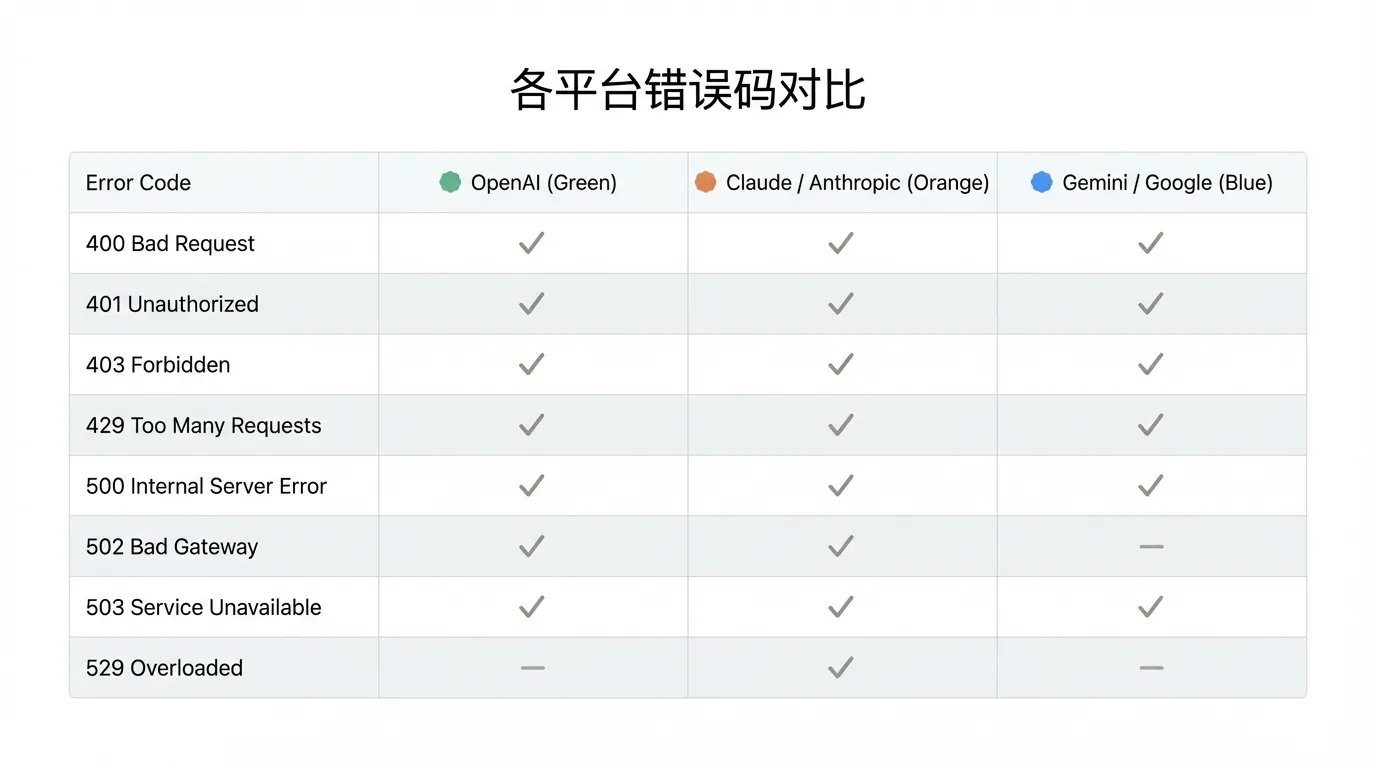
| 错误码 | OpenAI | Claude | Gemini | 含义 | 处理方式 |
|---|---|---|---|---|---|
| 400 | ✅ | ✅ | ✅ | 参数错误 | 检查请求格式 |
| 401 | ✅ | ✅ | ✅ | 认证失败 | 检查 API Key |
| 403 | ✅ | ✅ | ✅ | 权限不足 | 检查模型/区域权限 |
| 404 | ✅ | ✅ | ✅ | 资源不存在 | 检查模型名/端点 |
| 408 | ✅ | — | — | 请求超时 | 减少 Token/开 Stream |
| 429 | ✅ | ✅ | ✅ | 限流 | 指数退避 + 升级配额 |
| 500 | ✅ | ✅ | ✅ | 服务端错误 | 重试 |
| 502 | ✅ | ✅ | — | 网关错误 | 重试 |
| 503 | ✅ | ✅ | ✅ | 服务不可用 | 等待 + 重试 |
| 529 | — | ✅ | — | 过载 | 等待 + 重试 |
常见问题(FAQ)
Q:GPT API 一直报 429,充了钱还是不行怎么办?
充值后需要等待系统自动升级 Usage Tier,通常几分钟到几小时不等。你可以在 OpenAI 后台的 Limits 页面查看当前 Tier。如果确认 Tier 已升级但还是 429,检查是否是 TPM(Token 限流)而不是 RPM——长 prompt 很容易打满 TPM。
Q:AI API 调用太慢,有没有不换模型就能提速的方法?
有三个立竿见影的方法:① 开启 streaming 模式,首字节延迟从 3-5 秒降到 <1 秒;② 减少 prompt 长度和 max_tokens;③ 使用就近加速节点,国内开发者通过云加速可以减少 200-400ms 网络延迟。
Q:API Key 泄露到 GitHub 了怎么办?
立即到对应平台后台删除该 Key 并重新生成。OpenAI 和 Google 都有自动检测机制,发现 Key 出现在公开代码库后会自动吊销。以后建议用环境变量管理 Key,绝不硬编码到代码中。
Q:生产环境需要实现哪些错误处理?
至少需要:① 所有请求实现指数退避重试;② 区分客户端错误(4xx 不重试)和服务端错误(5xx 重试);③ 设置合理的超时时间(建议 30-60 秒);④ 记录错误日志,包含请求 ID 方便排查;⑤ 关键路径设置 fallback 模型。
Q:切到第三方 API 后报 invalid 'user_id' 怎么办?
OpenAI Chat Completions 的 messages 只允许 role/content/name/tool_calls/tool_call_id/refusal 这几个 key,不允许 user_id。Claude Code、Codex CLI 等客户端有时会把内部追踪字段透传到 messages 里,被严格校验的第三方网关拒绝。最快解决:升级客户端到最新版(已修复 sanitize 逻辑),或 claude -c / 删 session 文件重开会话清空脏 messages。用 ofox.ai 中转会自动剥离非标准 key,绕过这个问题。
Q:Claude Code 报 failed to start login: typeerror: fetch failed 怎么处理?
这是 Claude Code 用 undici 连 console.anthropic.com OAuth 流程时网络不通触发的连接超时。国内网络 + 公司代理 + IPv6 任一因素都可能引发。排查:curl -v https://console.anthropic.com 测网络、关 IPv6(NODE_OPTIONS="--dns-result-order=ipv4first")、设 HTTPS_PROXY、或者最快——把 ANTHROPIC_BASE_URL 指到 ofox 中转跳过整个 OAuth 流程,详见 Claude Code 接入 ofox 教程。
总结与行动建议
- 立即做:给所有 API 调用加上指数退避重试(参考上面的
call_with_retry) - 本周做:实现统一的错误处理封装(参考
RobustAIClient) - 长期做:搭建监控告警,记录每次调用的延迟、错误率、Token 消耗
延伸阅读: