GLM 5.2 на своём железе в 2026: оборудование, vLLM и сравнение цен с облаком
Self-host GLM 5.2 (753B MIT, контекст 1M): 8x H200 на vLLM FP8, 4x H100 на Q4 GGUF или Mac Studio на 2-bit. Сайзинг GPU, $/час vs план Z.ai за $30/мес, 4 движка с первого дня.
Релиз GLM 5.2 от Zhipu — это не просто очередной API. На этой неделе на HuggingFace выложили веса под лицензией MIT, и впервые frontier-модель класса 1M-контекста для кода можно реально скачать, проаудитить и запустить на собственном железе. Загвоздка в самом железе: 753B параметров под стол не влезают.
Что вы получаете, ставя GLM 5.2 у себя (короткий ответ за 30 секунд)
| Параметр | Значение |
|---|---|
| Что можно сделать сегодня | Скачать zai-org/GLM-5.2-FP8 с HuggingFace и поднять через vllm serve на одной ноде 8x H200 |
| Сколько места на диске | ~750 GB под FP8, ~1,5 TB под BF16, ~376 GB под Q4_K_M GGUF, ~241 GB под 2-bit UD-IQ2_XXS |
| Минимальная продакшен-стойка | 8x H200 141GB (FP8) или 4x H100 80GB (Q4_K_M GGUF через llama.cpp) |
| Стенд для энтузиаста | Mac Studio M3 Ultra с ≥256 GB unified memory (изначально M3 Ultra конфигурировался до 512 GB; топовый SKU снят с продаж в марте 2026), UD-IQ2_XXS на 3–9 токенах/сек |
| Движки, работающие с первого дня | vLLM v0.23.0+, SGLang v0.5.13.post1+, Transformers v5.12+ (линейка 5.x; v5.12.1 от 15 июня 2026), KTransformers v0.6.1+; llama.cpp для GGUF; xLLM v0.10.0+ |
| Лицензия | MIT — коммерческое использование, модификация, редистрибуция разрешены |
| Цена против хостинга | Нода 8x H200 в облаке — ~$30–$50/час; Pro Coding Plan у Z.ai — ~$30/мес. Self-host окупается где-то после 3000 промптов/день |
Ранние сторонние сигналы: бенчмарки + Code Arena Frontend
Zhipu выложил полную таблицу собственных бенчмарков прямо в релизе (см. README по адресу github.com/zai-org/GLM-5). Цифры, важные для решения по self-host:
| Бенчмарк | GLM 5.2 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 62.1 | 69.2 | 58.6 |
| Terminal-Bench 2.1 (Terminus-2) | 81.0 | 85.0 | 84.0 |
| Terminal-Bench 2.1 (Best Reported Harness) | 82.7 | 78.9 | 83.4 |
| AIME 2026 | 99.2 | 95.7 | 98.3 |
| GPQA-Diamond | 91.2 | 93.6 | 93.6 |
| MCP-Atlas (Public Set) | 76.8 | 77.8 | 75.3 |
| DeepSWE | 46.2 | 58.0 | 70.0 |
| HLE | 40.5 | 49.8* | 41.4* |
(* = с инструментами / раскрытыми вариациями harness — см. сноски в исходной таблице.) GLM 5.2 отстаёт от Opus 4.8 по чистому SWE-bench Pro (62.1 против 69.2), но обгоняет на «Best Reported Harness» в Terminal-Bench 2.1 (82.7 против 78.9) и на агентной математике (AIME 99.2 против 95.7). Чего нет в публичном наборе: SWE-bench Verified, LiveCodeBench и Aider polyglot — три канонических бенчмарка для агентного кода, на которые обычно опирается open-weights-сообщество.
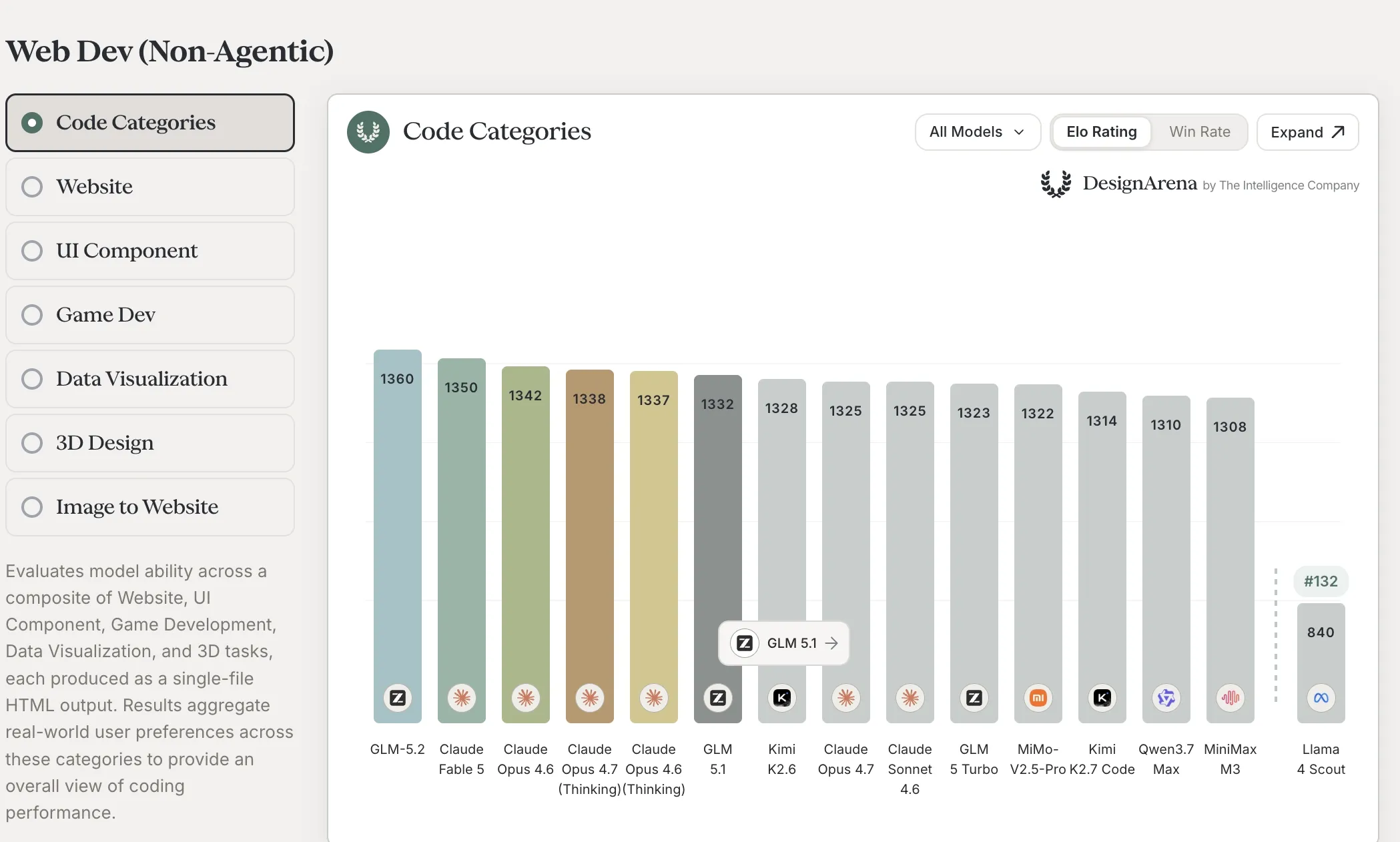
Две независимые сторонние таблицы от The Intelligence Company дали сигнал за 72 часа. На композите DesignArena Web Dev (Non-Agentic) GLM 5.2 на первом месте (Elo 1360, впереди Claude Fable 5 с 1350 и всего стека Claude Opus 4.6 / 4.7 / 4.7-Thinking). На отдельно хостящемся срезе Code Arena Frontend от Arena Intelligence — второе место (Elo 1595, позади Claude Fable 5 с 1654, у которого на этой странице явная пометка «not currently being sampled»).
![]()
Два угла на эти данные:
- Для решения по self-host: GLM 5.2 закрывает почти весь разрыв с Opus 4.8 в собственной таблице Zhipu и держится впереди GPT-5.5 на код-ориентированных эвалах, а на слепом голосовании DesignArena по web-dev — это вообще модель №1 в общем зачёте, обходящая все активно сэмплируемые версии Claude Opus в той же таблице. Отрыв от остального open-weights поля (Qwen 3.7 Max — 1310, Kimi K2.6 — 1328, GLM 5.1 — 1332) составляет 30–50 Elo на композите и 60+ Elo на frontend-срезе. Если вы уже выбирали open-weights под продакшен для кодинга, GLM 5.2 только что обогнал поле
- Для скептика: вендорская таблица бенчмарков остаётся вендорской — harness выбирал Zhipu. DesignArena меряет попарное слепое предпочтение на web-dev-выходах, а не end-to-end pass rate на отложенной выборке, а звёздочка на Fable 5 во frontend-срезе напоминает, что «ранг» может прыгнуть при возобновлении сэмплирования. Воспринимайте оба сигнала как сильные leading indicators, а не как замену собственным эвалам на своём коде
Когда self-host действительно ответ
Этот раздел позволяет закрыть пост и не читать остальное.
Когда GLM 5.2 стоит хостить у себя
- Data residency — код или промпты клиентов не имеют права покидать ваш VPC, регион или периметр железа
- Кастомный файнтюн — нужны LoRA или полный fine-tune на собственной кодовой базе, а хостинг такого API не даёт
- Air-gapped развёртывание — стенды, заводы, оборонка, изолированные сети, где любой исходящий трафик на
api.z.aiуже non-starter - Высокий устойчивый поток — вы выжигаете ≥3000 промптов/день, где амортизированное железо побеждает облачную ставку за промпт
Когда self-host НЕ ваш ответ
- Вы соло-разработчик или команда из двух человек. Pro Coding Plan у Z.ai за ~$30/мес покрывает ваш профиль за 1% от стоимости ноды 8x H200 в режиме 24/7. Читайте гайд по хостинг-доступу вместо этого
- У вас в продакшене ещё нет vLLM или SGLang. Стартовая стоимость (драйверный цикл, тюнинг KV-кэша, observability) — реальная и не отбивается минимум квартал
- Вам нужны именно благословлённые вендором цифры SWE-bench Verified, LiveCodeBench или Aider polyglot. Опубликованная таблица Zhipu покрывает SWE-bench Pro (62.1), Terminal-Bench 2.1 (81.0 / 82.7 best-harness), AIME 2026 (99.2), GPQA-Diamond (91.2), MCP-Atlas (76.8) и далее — таблица выше — но трёх бенчмарков, на которые опирается open-weights-сообщество при сравнении агентного кода, в ней пока нет. Независимых дельт качества по FP8 тоже ждать ещё несколько дней
Правило остановки
Если ваш пик — меньше 100 промптов/день и нет compliance-требования, которое исключает хостинг, не хостите сами. Берите Coding Plan, экономьте квартал инженерного времени и возвращайтесь, когда сработает один из четырёх триггеров выше.
Что реально доступно в день релиза
flowchart LR
HF[huggingface.co/zai-org] --> BF16[GLM-5.2 BF16<br/>~1.5 TB]
HF --> FP8[GLM-5.2-FP8<br/>~750 GB]
US[huggingface.co/unsloth] --> GGUF[GLM-5.2-GGUF<br/>Q4 376 GB / Q2 241 GB]
BF16 --> vLLM[vLLM 0.23+]
FP8 --> vLLM
FP8 --> SGLang[SGLang 0.5.13+]
GGUF --> Llama[llama.cpp]
GGUF --> LMS[LM Studio]| Источник | Репо / тег | Формат | Диск | Для чего |
|---|---|---|---|---|
| HF (официальный) | zai-org/GLM-5.2 | BF16 | ~1,5 TB | Ресёрч, файнтюн, максимальное качество в продакшене |
| HF (официальный) | zai-org/GLM-5.2-FP8 | F8_E4M3 | ~750 GB | Продакшен-инференс на H100/H200/MI300X |
| HF (комьюнити) | unsloth/GLM-5.2-GGUF | GGUF-кванты | 188–376 GB | llama.cpp, LM Studio, single-node для энтузиастов |
| Ollama | glm-5.2:cloud | Cloud-routed | n/a | Только удобство — не локальная загрузка |
Замечание про тег Ollama: на 17 июня 2026 запись glm-5.2:cloud на ollama.com/library/glm-5.2 — только облачная (суффикс :cloud маршрутизирует через хостинг Ollama, не на ваше железо). Тегов glm-5.2:latest или локального квантованного варианта в официальной библиотеке Ollama пока нет. Если хочется именно ollama-style эргономики для локального инференса, поднимите llama.cpp с Unsloth GGUF и оберните в Ollama-совместимый прокси.
Ещё стоит отметить: репозиторий Unsloth GGUF выложили за несколько часов до публикации этого поста; конкретные размеры файлов по квантам в UI HuggingFace на момент проверки ещё не показывались. Диапазон 188–376 GB выше посчитан по чистой арифметике битов-на-вес (188 GB при 2-bit, 376 GB при 4-bit на 753B параметров). Реальные размеры на диске могут оказаться на 10–20% больше из-за overhead — смотрите вкладку «Files and versions» перед загрузкой.
Сайзинг железа по уровню квантизации
Правильный уровень определяется тем, что влезает в VRAM после загрузки весов. KV-кэш — тихий убийца на контексте 1M.
| Уровень | Диск | Веса в VRAM | KV-кэш при ctx 256K | Минимальная продакшен-стойка |
|---|---|---|---|---|
| BF16 | ~1,5 TB | ~1,5 TB | ~50 GB | 16x H100 80GB (1,28 TB) или 8x H200 141GB (1,13 TB) — H200 впритык, может потребоваться offload |
| FP8 (E4M3) | ~750 GB | ~750 GB | ~25 GB на FP8 KV | 8x H200 141GB (1,13 TB) — комфортно; 8x H100 80GB (640 GB) — KV-кэш зажат |
| Q4_K_M GGUF | ~376 GB чистых весов (файл может быть больше из-за overhead) | ~376 GB | ~20 GB | 4x H100 80GB (320 GB) — впритык; 2x H200 141GB (282 GB) — рабочий вариант |
| Q2_K / UD-IQ2_XXS | ~188–241 GB | ~188–241 GB | ~15 GB | Одна рабочая станция: ≥256 GB DDR5 + 80 GB GPU offload или Mac Studio M3 Ultra с ≥256 GB unified memory |
Несколько правил, как применять эту таблицу:
- Оставляйте 20% запаса VRAM сверх суммы весов и KV. CUDA-фрагментация съест остаток, и отлаживать OOM на 90% prefill при запросе на 900K токенов вам точно не нужно
- KV-кэш растёт линейно с длиной контекста. Числа на 256K выше — иллюстративные; на 1M ждите ~4x по KV. Для продакшена на 1M почти всегда нужен FP8 KV (
--kv-cache-dtype fp8в vLLM) - GGUF на llama.cpp использует RAM хоста, а не VRAM — M3 Ultra работает потому, что его 256 GB UMA адресуются и CPU, и GPU. Рабочая станция с 256 GB DDR5 и GPU на 24 GB делает то же самое, только медленнее
Настройка vLLM (FP8 на 8x H200)
Этот путь выберет большинство продакшен-команд. vLLM v0.23.0 — минимум; патч-релизы выше дают прирост throughput, но FP8-путь GLM 5.2 работает уже на 0.23 GA.
Шаг 1: скачать веса
# Около 750 GB; на 10 GbE заложите 30–60 минут
huggingface-cli download zai-org/GLM-5.2-FP8 \
--local-dir /models/glm-5.2-fp8 \
--local-dir-use-symlinks FalseОжидаемый результат: 750 GB safetensors-шардов плюс config в /models/glm-5.2-fp8. Проверьте через du -sh /models/glm-5.2-fp8 и убедитесь, что в директории есть config.json и *.safetensors.index.json.
Шаг 2: запустить vLLM-сервер
vllm serve "zai-org/GLM-5.2-FP8" \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--port 8000Зачем эти флаги:
--tensor-parallel-size 8шардит 753B весов по 8 GPU. На H200 у вас 1,13 TB суммарной HBM — комфортно под FP8-веса плюс рабочий KV-кэш--max-model-len 262144стартует с 256K контекста. Поднимайте до 1048576 (1M) только после прогонов под реальную нагрузку, чтобы оценить давление KV-кэша--kv-cache-dtype fp8режет KV-кэш вдвое относительно дефолтного BF16, и это разница между 256K и 128K контекста на параллельный запрос--enable-prefix-cachingпереиспользует посчитанный KV для общих префиксов промпта — обязательная вещь для кодинг-агентов, которые гоняют один и тот же системный промпт сотни раз
Ожидаемый результат: в логах vLLM появится Available KV cache memory: X GB и Maximum concurrency for Y tokens: Z requests в течение ~3–5 минут после старта. Первый запрос займёт 30–90 секунд (компиляция + прогрев KV-кэша); последующие — субсекундно на коротких промптах.
Шаг 3: smoke-тест
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "zai-org/GLM-5.2-FP8",
"messages": [{"role":"user","content":"Reply with only the string OK."}],
"max_tokens": 16
}' | jq -r '.choices[0].message.content'Ожидаемый результат: OK или OK. за ~1 секунду. Если приходит 500 с out of memory или device-side assert, бюджет KV-кэша слишком тесен под выбранную длину — сбросьте --max-model-len до 131072 и повторите.
Настройка SGLang (FP8, RadixAttention)
SGLang — альтернативный продакшен-движок, и он обычно выигрывает по throughput на длинных контекстах, когда у вас тяжёлое переиспользование префиксов (многоходовые кодинг-агенты, RAG со стабильными system-промптами).
python -m sglang.launch_server \
--model-path zai-org/GLM-5.2-FP8 \
--tp 8 \
--context-length 262144 \
--kv-cache-dtype fp8_e4m3 \
--enable-mixed-chunk \
--port 30000RadixAttention в SGLang — главный выигрыш на длинном контексте: для кодинг-агента, который переиспользует 100K токенов системного промпта на каждом ходе, вы увидите ~3x запросов в секунду против vLLM 0.23 на том же железе. Цена — чуть выше инженерная поверхность (у RadixAttention своя история с observability).
Путь llama.cpp / Mac Studio (Q4 или Q2 GGUF)
Для возни, разработки прямо на ноутбуке или single-node air-gapped развёртывания llama.cpp с GGUF-квантами от Unsloth — самый дешёвый путь к «GLM 5.2 уже работает».
# Скачать 4-битный квант — подставьте имя файла под тот шард Q4_K_M, который опубликован
huggingface-cli download unsloth/GLM-5.2-GGUF \
GLM-5.2-Q4_K_M.gguf \
--local-dir /models/glm-5.2-gguf
# Собрать llama.cpp с CUDA (на Mac пропустите — Metal соберётся автоматически)
cmake -B llama.cpp/build -DGGML_CUDA=ON
cmake --build llama.cpp/build --config Release -j
# Поднять OpenAI-совместимый API на порту 8080
./llama.cpp/build/bin/llama-server \
--model /models/glm-5.2-gguf/GLM-5.2-Q4_K_M.gguf \
--ctx-size 32768 \
--n-gpu-layers 999 \
--host 0.0.0.0 --port 8080На M3 Ultra Mac Studio с 256 GB unified memory 2-bit UD-IQ2_XXS даёт ~3–9 токенов/сек в зависимости от длины контекста. Хватит для соло-работы с кодинг-агентом; не хватит для команды разработчиков. Для максимальной интерактивности на Mac сбросьте --ctx-size до 16K.
Цена: self-host против Z.ai Coding Plan
Утверждение «self-host экономит деньги» почти всегда ложно. Вот математика на ценах облака июня 2026.
| Сценарий | Железо | Месячная цена | Заметки |
|---|---|---|---|
| Хостинг (Z.ai Pro Coding Plan) | Нет | ~$30 | Потолок ~2000 промптов/нед |
| Хостинг (Z.ai Max Coding Plan) | Нет | ~$80 | Потолок ~8000 промптов/нед |
| Self-host на 8x H200 (облако, 24/7) | Reserved instance | ~$21–36k | Смешанная ставка $30–50/час |
| Self-host на 8x H200 (облако, on-demand 9–18) | То же железо, 200 ч/мес | ~$6–10k | Большинство команд 24/7 не гоняют |
| Self-host на своих 8x H200 | Capex + электричество | ~$3–5k/мес амортизированно | ~$200k железа на 4 года + питание |
| Self-host на 256 GB M3 Ultra | Своя рабочая станция | ~$50/мес амортизированно | Разово ~$8k; электричество ~$30/мес |
Точки безубыточности, которые стоит знать:
- Хостинг Pro против своего M3 Ultra: M3 Ultra выигрывает по амортизированной цене выше ~$30/мес хостинговой нагрузки, но только если 3–9 токенов/сек устраивает ваш рабочий процесс
- Хостинг Max против облачного 8x H200: нужно ~3000+ промптов/день и ~30%+ загрузки H200-ноды, чтобы облако обошло хостинг за $80/мес. Это команда из 20 разработчиков, постоянно гоняющая кодинг-агентов
- Свои 8x H200: побеждают по цене выше ~10000 промптов/день только если у вас реально есть дата-центровая ёмкость и операционная команда. Для большинства компаний это полугодовой цикл закупки до первого промпта
Закономерность: хостинг побеждает у 95% команд. Self-host выигрывает у тех 5%, у кого compliance, residency или устойчивый throughput перевешивают цену.
Частые ошибки при self-host-настройке
| Ошибка | Вероятная причина | Лечение |
|---|---|---|
CUDA out of memory при загрузке модели | Маленький TP или слишком щедрый бюджет KV-кэша | Поднимите --tensor-parallel-size до числа GPU; сбросьте --max-model-len до половины запланированного и наращивайте |
RuntimeError: FP8 ops not supported | GPU — Ampere (A100), а не Hopper (H100/H200) | FP8 E4M3 требует Hopper и новее. Владельцам A100 — Q4_K_M GGUF через llama.cpp |
Варнинг model has tied_word_embeddings: false | Несовпадение авто-детекта vLLM с config | Для GLM 5.2 безопасно игнорировать; config корректен |
| 504 / сброс соединения на запросах от 500K+ токенов | First-token latency превышает дефолтный клиентский таймаут | Поставьте клиентский таймаут 600s; для vLLM используйте --max-num-seqs 4, чтобы снизить число параллельных prefill |
IndexError в RadixAttention при первом запуске SGLang | Несовпадение кэша токенайзера | Удалите ~/.cache/sglang/ и перезапустите — кэш пересоберётся на первом инференсе |
GGUF падает с tensor not found: blk.X.attn_q.weight | Версия llama.cpp слишком старая для архитектуры GLM MoE DSA | Обновите llama.cpp до сборки ≥ дня публикации Unsloth GGUF; пересоберите cmake --build llama.cpp/build |
| Дико нестабильные выходы относительно Z.ai-хостинга | Не выровнены параметры сэмплинга | Сверьтесь с официальными дефолтами из huggingface.co/zai-org/GLM-5.2/generation_config.json: temperature 1.0, top_p 0.95 (top_k не задан); прогоните один и тот же промпт против обоих эндпоинтов для проверки паритета |
Когда self-host — неправильный ответ: альтернативы на ofox
Если математика self-host не сходится, но всё же хочется китайскую coding-модель за одним OpenAI-совместимым эндпоинтом, ofox перечисляет три альтернативы, доступных в день релиза:
| Модель | model ID на ofox | Контекст | Когда выбрать вместо self-host GLM 5.2 |
|---|---|---|---|
| DeepSeek V4 Pro | deepseek/deepseek-v4-pro | 1M | Нужны цифры SWE-bench Verified (DeepSeek их публикует; у GLM 5.2 в публичной таблице только SWE-bench Pro) и более длинная история в комьюнити |
| Kimi K2.6 | moonshotai/kimi-k2.6 | 262K | Нужен длинный контекст с независимо подтверждёнными бенчмарками, а не только «заявленными» |
| Qwen 3 Coder Next | bailian/qwen3-coder-next | 256K | Многоязычные кодовые базы (комментарии и идентификаторы на китайском / японском / корейском) |
Та же форма обвязки, что и для self-host-эндпоинта — меняется только base URL и model ID:
export OPENAI_BASE_URL="https://api.ofox.io/v1"
export OPENAI_API_KEY="ofox-..."
export OPENAI_MODEL="deepseek/deepseek-v4-pro"GLM 5.2 пока не числится в каталоге ofox на 17 июня 2026. Когда модель появится, переход с deepseek-v4-pro на будущий z-ai/glm-5.2 — это смена одной строки в этом конфиге. По хостинг-пути через Z.ai сегодня смотрите парный гайд по доступу к GLM 5.2 — там форма эндпоинта Z.ai Coding Plan, API-ключи и та же модель на официальном Anthropic-совместимом эндпоинте для пользователей Claude Code.
Observability, которую стоит иметь с первого дня
Три сигнала на продакшен-self-host GLM 5.2 не подлежат обсуждению:
- Tokens-per-second под нагрузкой — следите за p50 и p95 отдельно: один запрос с 900K контекста может утянуть p99 на порядок
- Утилизация KV-кэша — vLLM отдаёт
vllm:gpu_cache_usage_percна/metrics; как только устойчиво пробивается 90%, throughput схлопывается - Total tokens на запрос — кодинг-агенты дрейфуют в сторону прожига токенов на бесцельных рефакторингах; инструментируйте на уровне PR или сессии, чтобы поймать ушедший в петлю агент до того, как он съест бюджет
Прикрутите это к тому стеку, который у вас уже есть (Datadog, Honeycomb, Grafana — выберите один, не строите четвёртый). Для SGLang эквивалентные метрики живут на /metrics_collect.
Источники
- Официальная карточка модели HuggingFace — https://huggingface.co/zai-org/GLM-5.2
- Карточка FP8-модели HuggingFace — https://huggingface.co/zai-org/GLM-5.2-FP8
- README репозитория GLM-5 от Zhipu — https://github.com/zai-org/GLM-5
- Лидерборд DesignArena — https://www.designarena.ai/leaderboard
- Arena Intelligence Code Arena Frontend — https://arena.ai/leaderboard/code
- Страница библиотеки Ollama — https://ollama.com/library/glm-5.2
- Комьюнити-кванты Unsloth GGUF — https://huggingface.co/unsloth/GLM-5.2-GGUF
- Каталог моделей ofox — https://ofox.io/en/models
- Парный гайд по доступу на ofox — https://ofox.io/ru/blog/glm-5-2-access-guide-2026/
- Тред обсуждения на Reddit r/LocalLLaMA — https://www.reddit.com/r/LocalLLaMA/comments/1u7o9vp/glm_52_api_is_live_weights_are_on_hf_and_ollama/
- PyPI индекс версий — https://pypi.org/project/transformers/,
Самое интересное в этом релизе — не контекст 1M и не FP8-сборка, а то, что впервые open-weights frontier-модель с реальной репутацией на коде влезает в закупочный бюджет средней исследовательской лаборатории. Следующие 90 дней покажут, сможет ли комьюнити выкатить FP4-кванты и снизить продакшен-стойку с 8x H200 до 4x H100. Если получится — математика self-host перевернётся.


