2026年版 GLM 5.2 セルフホスト実践 — ハードウェア、vLLM、クラウドとのコスト比較
GLM 5.2 (753B MIT、1M ctx) を自前で動かす。8x H200 (vLLM FP8)、4x H100 (Q4 GGUF)、Mac Studio (2-bit) のサイジング、クラウド GPU 時間単価 vs Z.ai $30/月、day-one 対応 4 エンジンを実機目線で整理。
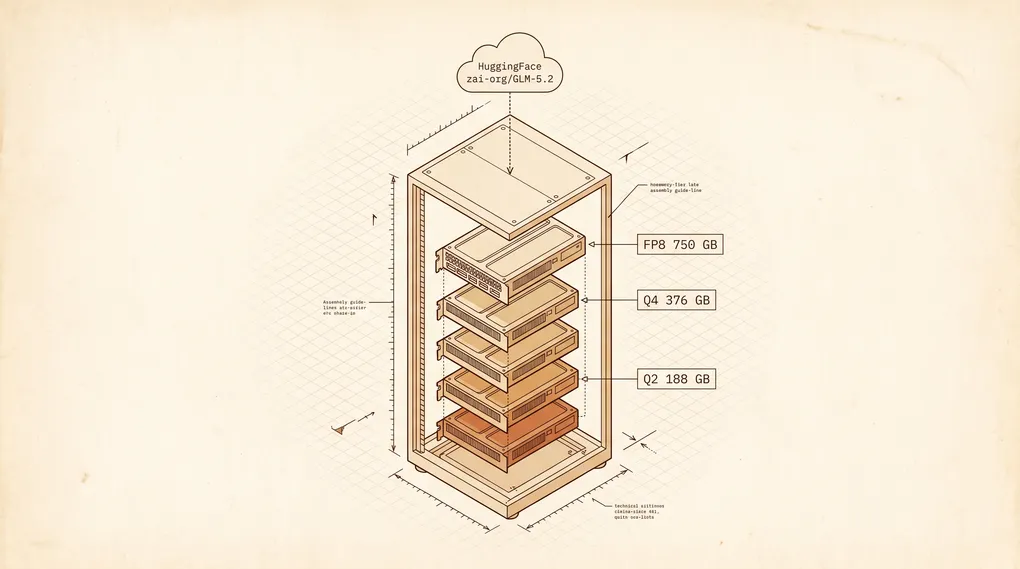
Zhipu の GLM 5.2 は単なる API リリースではありません。MIT ライセンスのウェイトが今週 HuggingFace に到着したことで、フロンティア級の 1M コンテキスト・コーディングモデルを自分のメタルに pull し、監査し、本当に動かせるようになりました — 史上初めて。問題はそのメタルで、753B パラメータはデスクの下のノート PC には収まりません。
GLM 5.2 をセルフホストすると何が得られるか (30 秒回答)
| 項目 | 内容 |
|---|---|
| 今日できること | zai-org/GLM-5.2-FP8 を HuggingFace から pull し、単一の 8x H200 ノードで vllm serve で配信 |
| ディスク要件 | FP8 で約 750 GB、BF16 で約 1.5 TB、Q4_K_M GGUF で約 376 GB、2-bit UD-IQ2_XXS で約 241 GB |
| 本番最小構成 | 8x H200 141GB (FP8) または 4x H100 80GB (llama.cpp 経由の Q4_K_M GGUF) |
| ホビイスト構成 | ユニファイドメモリ 256 GB 以上の Mac Studio M3 Ultra (M3 Ultra は当初 512 GB まで構成可能でしたが、最上位 SKU は 2026 年 3 月で販売終了)。UD-IQ2_XXS で 3〜9 tokens/sec |
| Day-one 対応エンジン | vLLM v0.23.0+、SGLang v0.5.13.post1+、Transformers v5.12+ (5.x 系、v5.12.1 が 2026/6/15 リリース)、KTransformers v0.6.1+、GGUF 用に llama.cpp、xLLM v0.10.0+ |
| ライセンス | MIT — 商用利用・改変・再配布すべて可 |
| ホスト型とのコスト感 | クラウドの 8x H200 ノードは時間あたり約 $30〜50。Z.ai の Pro Coding Plan は月額約 $30。セルフホストの損益分岐は 1 日 3,000 プロンプトを超えた辺り |
第三者シグナル — ベンチマークと Code Arena Frontend
Zhipu はリリースと同時に first-party ベンチマーク表を公開しています (github.com/zai-org/GLM-5 の README を参照)。セルフホスト判断に効く数字は次のとおり。
| ベンチマーク | GLM 5.2 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 62.1 | 69.2 | 58.6 |
| Terminal-Bench 2.1 (Terminus-2) | 81.0 | 85.0 | 84.0 |
| Terminal-Bench 2.1 (Best Reported Harness) | 82.7 | 78.9 | 83.4 |
| AIME 2026 | 99.2 | 95.7 | 98.3 |
| GPQA-Diamond | 91.2 | 93.6 | 93.6 |
| MCP-Atlas (Public Set) | 76.8 | 77.8 | 75.3 |
| DeepSWE | 46.2 | 58.0 | 70.0 |
| HLE | 40.5 | 49.8* | 41.4* |
(* = ツール併用または開示済みハーネス差分あり — 脚注は原典の表を参照。) GLM 5.2 は素の SWE-bench Pro で Opus 4.8 に届かない (62.1 vs 69.2) ものの、Terminal-Bench 2.1 の “Best Reported Harness” では逆転 (82.7 vs 78.9)、エージェント数学の AIME でも 99.2 vs 95.7 で先行しています。公開セットでまだ欠けているのは SWE-bench Verified、LiveCodeBench、Aider polyglot の 3 つ — オープンウェイト界隈が普段拠り所にする御三家です。
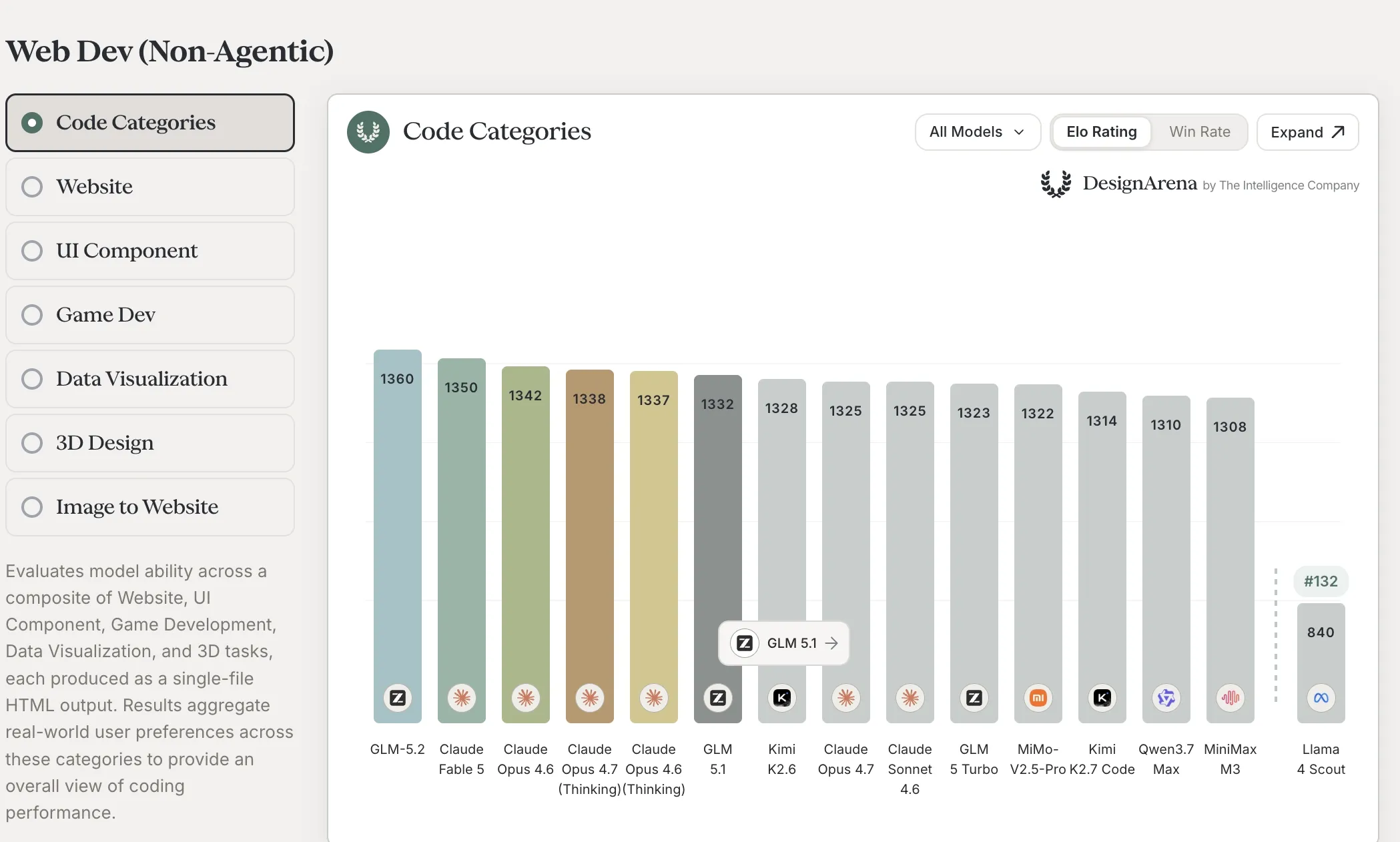
The Intelligence Company による第三者リーダーボード 2 種も 72 時間以内にシグナルを出してきました。DesignArena の Web Dev (Non-Agentic) コンポジットで GLM 5.2 は 1 位 (Elo 1,360、Claude Fable 5 の 1,350、および Claude Opus 4.6 / 4.7 / 4.7-Thinking 一式を上回る)。別ドメインで運用される Arena Intelligence の Code Arena Frontend では 2 位 (Elo 1,595、Claude Fable 5 の 1,654 に次ぐ — そのビューでは “not currently being sampled” のアスタリスクが付いています)。
![]()
このエビデンスの読み方は 2 つあります。
- セルフホスト判断側: GLM 5.2 は Zhipu の first-party 表で Opus 4.8 にほぼ追いつき、コーディング寄り評価では GPT-5.5 を上回ります。DesignArena のブラインド選好型 Web Dev コンポジットでは、現役サンプリング中の Claude Opus 全変種を抜いて総合 1 位。オープンウェイト陣の他勢 (Qwen 3.7 Max 1,310、Kimi K2.6 1,328、GLM 5.1 1,332) とは、コンポジットで 30〜50 Elo、Frontend スライスでは 60 Elo 以上の差。本番コーディング用にオープンウェイトを検討していたなら、GLM 5.2 は一気に頭一つ抜けました
- 懐疑論者側: ベンダー製のベンチ表はベンダー製のベンチ表 — ハーネスを選んだのは Zhipu です。DesignArena は Web 開発出力の二者択一ブラインド選好を測っているのであって、ホールドアウトでのエンドツーエンド合格率ではありません。Frontend スライスの Fable 5 アスタリスクは、サンプリングが再開すると順位は動くという注意書きでもあります。どちらも強い先行指標として扱うべきで、自分のコードベースでの実機評価の代わりにはなりません
デシジョンフレーム — セルフホストが本当に答えになるのはいつか
このセクションで結論が出れば、以降を読む必要はありません。
セルフホストすべきとき
- データ所在地 — 顧客のコードやプロンプトを自社 VPC、リージョン、ハードウェア境界の外に出せない
- 独自ファインチューン — 自社コードベースに対する LoRA やフルファインチューンが必要で、ホスト API がその面を公開していない
- エアギャップ運用 — ベンチ、工場、防衛、制限ネットワーク環境など、
api.z.aiへの外向き通信が論外 - 持続的な高スループット — 1 日 3,000 プロンプト以上をコンスタントに焼いており、ハード償却がプロンプト単価のクラウドより安くなる
セルフホストすべきでないとき
- 個人開発者か 2 人チーム。Z.ai Pro Coding Plan の月額約 $30 が、8x H200 を 24/7 動かすコストの 1% で利用量をカバーします。代わりに ホスト経由のアクセスガイド を読んでください
- vLLM や SGLang を本番で運用していない。セットアップコスト (ドライバ寿命管理、KV キャッシュチューニング、観測) は実在し、少なくとも 1 四半期は回収できません
- ベンダー公認の SWE-bench Verified、LiveCodeBench、Aider polyglot の数字が個別に必要。Zhipu の公開表は SWE-bench Pro (62.1)、Terminal-Bench 2.1 (81.0 / Best-Harness 82.7)、AIME 2026 (99.2)、GPQA-Diamond (91.2)、MCP-Atlas (76.8) などを含みますが — 上の表を参照 — オープンウェイト界隈がエージェント・コーディングで参照する 3 つはまだありません。FP8 の品質差分も独立検証はあと数日
ストップルール
ピーク負荷が 1 日 100 プロンプト未満で、ホスト型を否定するコンプライアンス要件もないなら、セルフホストは禁止。Coding Plan を使い、エンジニアリング工数を 1 四半期分節約して、上記 4 つのトリガーのどれかが実際に発火したときに再検討してください。
Day-one で実際に使えるもの
flowchart LR
HF[huggingface.co/zai-org] --> BF16[GLM-5.2 BF16<br/>~1.5 TB]
HF --> FP8[GLM-5.2-FP8<br/>~750 GB]
US[huggingface.co/unsloth] --> GGUF[GLM-5.2-GGUF<br/>Q4 376 GB / Q2 241 GB]
BF16 --> vLLM[vLLM 0.23+]
FP8 --> vLLM
FP8 --> SGLang[SGLang 0.5.13+]
GGUF --> Llama[llama.cpp]
GGUF --> LMS[LM Studio]| 提供元 | リポジトリ / タグ | フォーマット | ディスク | 向き |
|---|---|---|---|---|
| HF (公式) | zai-org/GLM-5.2 | BF16 | 約 1.5 TB | 研究、ファインチューン、最高品質の本番 |
| HF (公式) | zai-org/GLM-5.2-FP8 | F8_E4M3 | 約 750 GB | H100 / H200 / MI300X 上の本番推論 |
| HF (コミュニティ) | unsloth/GLM-5.2-GGUF | GGUF 量子化 | 188〜376 GB | llama.cpp、LM Studio、1 ノードのホビイスト |
| Ollama | glm-5.2:cloud | クラウドルーティング | 該当なし | 利便性のみ — ローカルダウンロード不可 |
Ollama タグに関する注意: 2026 年 6 月 17 日時点、ollama.com/library/glm-5.2 の glm-5.2:cloud エントリは cloud-only (:cloud サフィックスは Ollama のホスト推論経由で、自機では動きません)。公式 Ollama ライブラリには glm-5.2:latest もローカル量子化タグもまだありません。Ollama 風の操作感でローカル推論をしたい場合は、Unsloth の GGUF を llama.cpp で動かし、Ollama 互換プロキシで包んでください。
もう 1 点フラグ立て: Unsloth GGUF リポジトリは本記事公開の数時間前に作成されたばかりで、検証時点では HuggingFace UI に量子化別ファイルサイズがまだ載っていません。上の 188〜376 GB は raw bits-per-weight (753B パラメータで 2-bit = 188 GB、4-bit = 376 GB) からの計算値です。実ファイルはオーバーヘッドで 10〜20% 大きくなる可能性があるため、pull する前にライブの「Files and versions」タブを確認してください。
量子化階層別ハードウェアサイジング
正しい階層は、モデルウェイトロード後に VRAM に残る容量で決まります。1M コンテキストでは KV キャッシュがサイレントキラーです。
| 階層 | ディスク | VRAM 上のウェイト | KV キャッシュ (256K ctx) | 本番最小構成 |
|---|---|---|---|---|
| BF16 | 約 1.5 TB | 約 1.5 TB | 約 50 GB | 16x H100 80GB (1.28 TB) または 8x H200 141GB (1.13 TB) — H200 はタイト、オフロード必要かも |
| FP8 (E4M3) | 約 750 GB | 約 750 GB | FP8 KV で約 25 GB | 8x H200 141GB (1.13 TB) — 余裕。8x H100 80GB (640 GB) — KV キャッシュ制約あり |
| Q4_K_M GGUF | 約 376 GB (ファイルはオーバーヘッドで大きくなる可能性) | 約 376 GB | 約 20 GB | 4x H100 80GB (320 GB) — タイト、2x H200 141GB (282 GB) — 実用域 |
| Q2_K / UD-IQ2_XXS | 約 188〜241 GB | 約 188〜241 GB | 約 15 GB | 単一ワークステーション: DDR5 256 GB 以上 + 80 GB GPU オフロード、または Mac Studio M3 Ultra (ユニファイドメモリ 256 GB 以上) |
この表を運用に落とすときの経験則。
- ウェイト + KV の合計に対して VRAM の 20% を余白として残す。CUDA フラグメンテーションが残りを食い、900K トークンリクエストのプリフィル 90% で OOM デバッグはやりたくありません
- KV キャッシュはコンテキスト長に対して線形にスケール。上の 256K の数字は説明用で、1M コンテキストでは約 4 倍を見込んでください。1M 本番運用ではほぼ確実に FP8 KV キャッシュ (vLLM の
--kv-cache-dtype fp8) を使うべきです - llama.cpp の GGUF はホスト RAM を使い、VRAM ではない — M3 Ultra で動くのは 256 GB UMA が CPU と GPU の両方からアドレッシング可能だから。256 GB DDR5 ワークステーション + 24 GB GPU でも同じことができますが、遅くなります
vLLM セットアップ (8x H200 上の FP8)
本番チームの大半が選ぶ経路です。vLLM v0.23.0 が最低要件 — 後続パッチリリースでスループットが伸びますが、FP8 GLM 5.2 経路は 0.23 GA で動きます。
Step 1: ウェイトを pull
# 約 750 GB、10 GbE 接続で 30〜60 分を見込む
huggingface-cli download zai-org/GLM-5.2-FP8 \
--local-dir /models/glm-5.2-fp8 \
--local-dir-use-symlinks False期待結果: /models/glm-5.2-fp8 配下に safetensors シャード 750 GB と config 一式。du -sh /models/glm-5.2-fp8 でサイズを確認し、config.json と *.safetensors.index.json がディレクトリに含まれることをチェックしてください。
Step 2: vLLM サーバを起動
vllm serve "zai-org/GLM-5.2-FP8" \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--port 8000各フラグの理由:
--tensor-parallel-size 8で 753B ウェイトを 8 GPU にシャーディング。H200 なら 1.13 TB の集約 HBM があり、FP8 ウェイト + 実用 KV キャッシュで余裕--max-model-len 262144は 256K コンテキストでスタート。実ワークロードで KV キャッシュ圧を計測したあとに 1048576 (1M) まで上げる--kv-cache-dtype fp8で KV キャッシュをデフォルト BF16 の半分に圧縮 — 同時リクエストごとに 256K か 128K かを分ける肝--enable-prefix-cachingで共有プロンプト・プレフィックスの計算済み KV を再利用 — 同じシステムプロンプトを数百回叩くコーディングエージェントには必須
期待結果: 起動から約 3〜5 分で vLLM が Available KV cache memory: X GB と Maximum concurrency for Y tokens: Z requests をログに出します。初回リクエストは 30〜90 秒 (コンパイル + KV キャッシュウォームアップ)、以降の短いプロンプトは秒未満。
Step 3: スモークテスト
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "zai-org/GLM-5.2-FP8",
"messages": [{"role":"user","content":"Reply with only the string OK."}],
"max_tokens": 16
}' | jq -r '.choices[0].message.content'期待結果: 約 1 秒以内に OK または OK.。out of memory や device-side assert を含む 500 が返ってきたら、KV キャッシュ予算がモデル長に対して厳しすぎる — --max-model-len を 131072 に落として再試行してください。
SGLang セットアップ (FP8、RadixAttention)
SGLang は本番代替エンジンで、共有プレフィックス再利用が多いワークロード (マルチターンのコーディングエージェント、安定したシステムプロンプトを伴う RAG) では長コンテキスト・スループットで勝つ傾向があります。
python -m sglang.launch_server \
--model-path zai-org/GLM-5.2-FP8 \
--tp 8 \
--context-length 262144 \
--kv-cache-dtype fp8_e4m3 \
--enable-mixed-chunk \
--port 30000SGLang の RadixAttention は長コンテキストの勝ち手 — ターンごとに 100K トークンのシステムプロンプトを再利用するコーディングエージェントなら、同じハードで vLLM 0.23 比 約 3 倍 の requests/sec が出ます。トレードオフはエンジニアリング表面がやや広い (RadixAttention 固有の観測ストーリーが要る) こと。
llama.cpp / Mac Studio 経路 (Q4 または Q2 GGUF)
試行錯誤、ラップトップ開発、1 ノードのエアギャップ運用には、Unsloth GGUF + llama.cpp が「GLM 5.2 を動かす」の最安経路です。
# 4-bit 量子化を pull — 公開された Q4_K_M シャードのファイル名に合わせて調整
huggingface-cli download unsloth/GLM-5.2-GGUF \
GLM-5.2-Q4_K_M.gguf \
--local-dir /models/glm-5.2-gguf
# CUDA 付きで llama.cpp をビルド (Mac はスキップ — Metal は自動)
cmake -B llama.cpp/build -DGGML_CUDA=ON
cmake --build llama.cpp/build --config Release -j
# OpenAI 互換 API を port 8080 で配信
./llama.cpp/build/bin/llama-server \
--model /models/glm-5.2-gguf/GLM-5.2-Q4_K_M.gguf \
--ctx-size 32768 \
--n-gpu-layers 999 \
--host 0.0.0.0 --port 8080ユニファイドメモリ 256 GB の M3 Ultra Mac Studio では、2-bit UD-IQ2_XXS でコンテキスト長に応じて約 3〜9 tokens/sec。個人のコーディングエージェント用途には十分、複数開発者チーム用途には足りない。Mac では --ctx-size を 16K に落とすとインタラクティブ・スループットが最大化します。
コスト — セルフホスト vs Z.ai Coding Plan
「セルフホストは安い」という主張は、ほぼ常に間違いです。2026 年 6 月のクラウド価格で計算してみます。
| シナリオ | ハードウェア | 月額 | 備考 |
|---|---|---|---|
| ホスト (Z.ai Pro Coding Plan) | なし | 約 $30 | 週 2,000 プロンプトの上限 |
| ホスト (Z.ai Max Coding Plan) | なし | 約 $80 | 週 8,000 プロンプトの上限 |
| セルフホスト 8x H200 (クラウド、24/7) | リザーブドインスタンス | 約 $21k〜36k | 平均レート $30〜50/時 |
| セルフホスト 8x H200 (クラウド、平日 9〜17 時) | 同上、月 200 時間 | 約 $6k〜10k | ほとんどのチームは 24/7 では走らせない |
| セルフホスト 自社所有 8x H200 | Capex + 電気代 | 約 $3k〜5k/月 償却ベース | 約 $200k のハードを 4 年償却 + 電力 |
| セルフホスト 256 GB M3 Ultra | 自社ワークステーション | 約 $50/月 償却ベース | 一括約 $8k + 電気代約 $30/月 |
抑えておくべき損益分岐:
- ホスト Pro vs 自社所有 M3 Ultra: M3 Ultra が償却コストで勝つのは月 $30 を超えるホスト使用量から — ただし 3〜9 tokens/sec で運用が回る場合のみ
- ホスト Max vs クラウド 8x H200: クラウドが月 $80 のホストに勝つには 1 日 3,000+ プロンプトかつ H200 ノードのデューティサイクル 30%+ が必要。20 人規模のチームがコーディングエージェントを常時回している状態
- 自社所有 8x H200: 1 日 10,000 プロンプトを超えてようやく勝つ — ただしデータセンター容量と運用チームが既にある場合に限る。多くの会社では最初のプロンプトが走るまでに 6 ヶ月の調達サイクル
パターンは明快: 95% のチームはホストが勝つ。セルフホストが勝つのは、コンプライアンス、データ所在地、持続スループットが価格を上回る 5%。
セルフホスト構築でよく出るエラー
| エラー | 想定原因 | 対処 |
|---|---|---|
モデルロード中の CUDA out of memory | TP サイズが低すぎる、または KV キャッシュ予算が大きすぎる | --tensor-parallel-size を GPU 数に合わせる、--max-model-len を予定値の半分に落として段階的に増やす |
RuntimeError: FP8 ops not supported | GPU が Ampere (A100) で Hopper (H100/H200) ではない | FP8 E4M3 は Hopper 以降が必要。A100 オーナーは llama.cpp の Q4_K_M GGUF を使うこと |
model has tied_word_embeddings: false の警告 | vLLM の自動検出と config の食い違い | GLM 5.2 では無視可 — config は正しい |
| 500K+ トークンリクエストでの 504 / connection reset | 初トークン遅延がクライアントのデフォルトタイムアウトを超えた | クライアントタイムアウトを 600 秒に。vLLM では --max-num-seqs 4 で同時プリフィルを抑える |
SGLang 初回起動時の RadixAttention 内 IndexError | トークナイザキャッシュの不整合 | ~/.cache/sglang/ を削除して再起動 — 初回推論でキャッシュが再構築される |
tensor not found: blk.X.attn_q.weight で GGUF ロードが失敗 | llama.cpp のバージョンが古く GLM MoE DSA に未対応 | Unsloth GGUF 公開日以降のビルドに更新、cmake --build llama.cpp/build で再ビルド |
| Z.ai ホスト版と出力が大きくブレる | サンプリングパラメータの不一致 | huggingface.co/zai-org/GLM-5.2/generation_config.json の公式デフォルト (temperature 1.0、top_p 0.95、top_k 未設定) に揃え、同じプロンプトを両エンドポイントに投げて一致を確認 |
セルフホストが正解でないとき — ofox 経由の代替
セルフホストの算盤が合わないが OpenAI 互換エンドポイント 1 本で中国系コーディングモデルを使いたい場合、ofox には Day-one から動く代替が 3 つあります。
| モデル | ofox モデル ID | コンテキスト | GLM 5.2 セルフホストの代わりに選ぶ理由 |
|---|---|---|---|
| DeepSeek V4 Pro | deepseek/deepseek-v4-pro | 1M | SWE-bench Verified の数字が欲しい (DeepSeek は公表、GLM 5.2 の公開表は SWE-bench Pro のみ)、長いコミュニティトラックレコードが欲しい |
| Kimi K2.6 | moonshotai/kimi-k2.6 | 262K | 長コンテキストで「公称」ではなく独立ベンチが取れているものが欲しい |
| Qwen 3 Coder Next | bailian/qwen3-coder-next | 256K | 多言語コードベース (中国語 / 日本語 / 韓国語のコメントや識別子) を扱う |
配線形はセルフホストエンドポイントと同じ — base URL と model ID を変えるだけです。
export OPENAI_BASE_URL="https://api.ofox.io/v1"
export OPENAI_API_KEY="ofox-..."
export OPENAI_MODEL="deepseek/deepseek-v4-pro"2026 年 6 月 17 日時点で GLM 5.2 は ofox カタログに未掲載。掲載されたら deepseek-v4-pro から将来の z-ai/glm-5.2 への切り替えは設定 1 行差し替えで完了します。今すぐ Z.ai 経由のホストルートを使う場合は、Z.ai Coding Plan エンドポイントの形、API キー、Claude Code ユーザ向けの Anthropic 互換エンドポイントまでをカバーした GLM 5.2 アクセスガイド を参照してください。
最初の日から欲しい観測項目
セルフホスト本番 GLM 5.2 で外せないシグナルは 3 つ。
- Tokens-per-second の負荷時計測 — p50 / p95 は別個に追跡すること。900K コンテキストの 1 リクエストだけで p99 が桁違いに引っ張られます
- KV キャッシュ使用率 — vLLM は
/metricsでvllm:gpu_cache_usage_percを公開。90% を持続的に超えたらスループットが崩れます - リクエストあたり総トークン数 — コーディングエージェントは深掘りリファクタで予算を焼きがち。PR / セッション単位で計測し、暴走ループが予算を食い尽くす前に検知できる体制を作る
既存スタック (Datadog、Honeycomb、Grafana — どれか 1 つ、4 つ目を自作しない) に接続してください。SGLang では同等メトリクスが /metrics_collect にあります。
参考リンク
- HuggingFace 公式モデルカード — https://huggingface.co/zai-org/GLM-5.2
- HuggingFace FP8 モデルカード — https://huggingface.co/zai-org/GLM-5.2-FP8
- Zhipu GLM-5 GitHub README — https://github.com/zai-org/GLM-5
- DesignArena リーダーボード — https://www.designarena.ai/leaderboard
- Arena Intelligence Code Arena Frontend — https://arena.ai/leaderboard/code
- Ollama ライブラリページ — https://ollama.com/library/glm-5.2
- Unsloth GGUF コミュニティ量子化 — https://huggingface.co/unsloth/GLM-5.2-GGUF
- ofox モデルカタログ — https://ofox.io/en/models
- 同伴の ofox アクセスガイド — https://ofox.io/blog/glm-5-2-access-guide-2026/
- Reddit r/LocalLLaMA スレッド — https://www.reddit.com/r/LocalLLaMA/comments/1u7o9vp/glm_52_api_is_live_weights_are_on_hf_and_ollama/
- PyPI バージョンインデックス — https://pypi.org/project/transformers/
このリリースの一番面白いところは 1M コンテキストでも FP8 公開でもありません — 本格的なコーディング系譜を持つオープンウェイト・フロンティアモデルが、史上初めて中規模研究ラボの調達予算に収まるサイズに収まったことです。これから 90 日で見極めるべきは、コミュニティが FP4 量子化を出してきて本番構成を 8x H200 から 4x H100 に落とせるかどうか。それが起これば、セルフホストの算盤は反転します。


