エージェントループ向け Gemini 3.1 Flash Lite vs DeepSeek V4 Flash
トークン単価では DeepSeek V4 Flash が安いが、総コストでは Flash Lite の BFCL v3 76.5% が勝つことも多い。エージェントループの計算とツール呼び出しの信頼性を分解する。
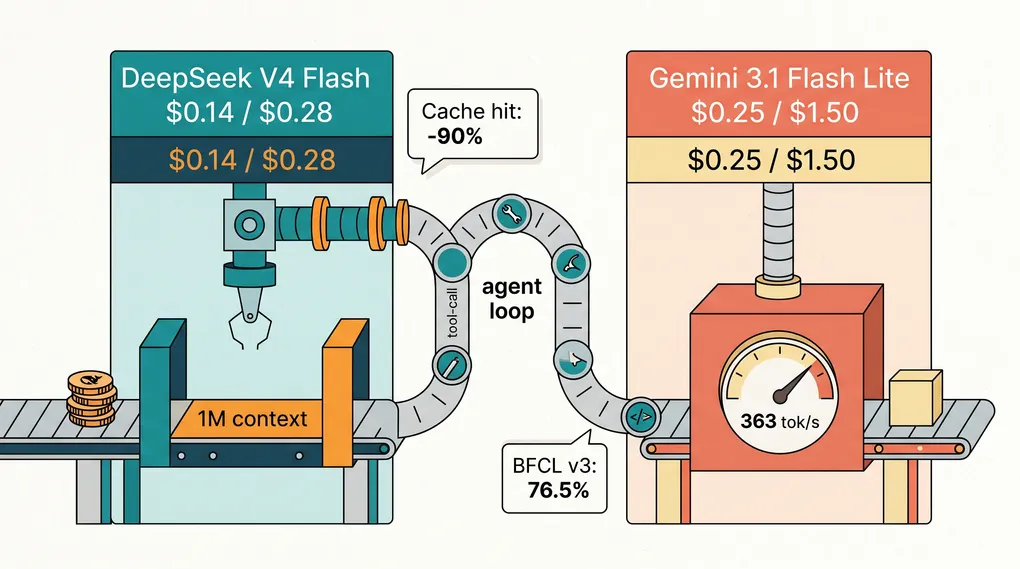
TL;DR — DeepSeek V4 Flash は生の API として安く、Gemini 3.1 Flash Lite はエージェントとして信頼できる。問うべきは「トークンあたりどちらが安いか」ではなく「ループを完了させるのに総トークンを少なく済ませるのはどちらか」だ。システムプロンプトが安定した範囲限定のループでは、キャッシュヒットが効き始めれば DeepSeek が両方の軸で勝つ。ツール呼び出しのチェーンが長く、なじみのない API を扱う場面では、Flash Lite の BFCL v3 76.5% と速い time-to-first-token が、一発で完了することで価格プレミアムを取り戻す。エージェントループの実行コストが $0.50 で、DeepSeek が2回必要なところを Flash Lite が1回で済むなら、節約分はすでに失われている。
セール — 新規ユーザーに $5 の無料クレジット — DeepSeek V4 Flash と Gemini 3.1 Flash Lite を1つの ofox.ai キーで実行、SDK の配線変更は不要。
2つのモデル、マーケティング抜きで
まず整理しておこう。「Gemini 3.1 Flash」という単独のティアは2026年5月時点で存在しない。Google が出しているのは Gemini 3.1 Flash Lite Preview と Gemini 3 Flash Preview だ。ベンチマークで「3.1 Flash」と言うとき、たいていは Flash Lite を指している。標準の「Flash」系列はいまだ3.0リリースのままで、価格は100万トークンあたり入力 $0.50、出力 $3.00 だ。予算重視のエージェントループでは、Flash Lite が該当する Google 製品になる。
| モデル | アーキテクチャ | コンテキスト | 出力上限 | 定価 (入力 / 出力, 100万あたり) |
|---|---|---|---|---|
| Gemini 3.1 Flash Lite Preview | Dense | 1,048,576 | 65,536 | $0.25 / $1.50 |
| DeepSeek V4 Flash | MoE (284B total, 13B active) | 1,000,000 | 384,000 | $0.14 / $0.28 |
両モデルとも ofox で定価で利用できる(ofox モデルカタログ、2026-05-14 検証)。DeepSeek V4 Flash にはさらに手厚いキャッシュヒットのリベートがある。キャッシュ済み入力は100万トークンあたり $0.0028 で、キャッシュミスに対して98%の割引だ(2026-04-26 にローンチ料金の1/10に引き下げ)。Gemini 3.1 Flash Lite もテキストのキャッシュ読み込みを100万トークンあたり $0.025(音声は $0.05)で提供しているが、DeepSeek のキャッシュ料金のおよそ9倍だ(Google Gemini API pricing、2026-05-14 検証)。
出力上限の違いは最初に指摘しておく価値がある。DeepSeek V4 Flash は1ターンで最大384Kの出力トークンを出せるが、Flash Lite は65Kで頭打ちになる。長い構造化レポート(網羅的なテスト計画や、複数ファイルのリファクタリングを単一レスポンスとして出力するもの)を生成するエージェントループでは、チャンク分割を強いられるまでに DeepSeek の方が余裕がある。
1億トークンの実際のコスト
現実的なエージェントワークロードで計算してみよう。コーディングエージェントが月に7000万の入力トークンを処理し、3000万の出力トークンを出すと仮定する。自動リファクタリング、テスト生成、ドキュメント作成ジョブを回す、典型的な中規模チームのケースだ。
定価、キャッシュヒットなしの場合:
| モデル | 入力コスト | 出力コスト | 月間合計 |
|---|---|---|---|
| DeepSeek V4 Flash | $9.80 | $8.40 | $18.20 |
| Gemini 3.1 Flash Lite | $17.50 | $45.00 | $62.50 |
DeepSeek はエンドツーエンドで3.4倍安い。差が開くのは出力側だ。Flash Lite の $1.50/M という出力料金は、冗長なツール呼び出しの理由づけや長いコードブロックを出すエージェントループにとって、実質的な税金になる。
次にキャッシュヒットを織り込む。システムプロンプトが安定したエージェントループのほとんどは60〜75%の範囲に収まる。ツール結果のたびにコンテキストの一部が無効化されるため、マーケティング資料で見かける90%超の数字は、現実のワークロードに触れると生き残らない(これは V4 Pro vs Flash の分析 で詳しく扱っている)。
キャッシュヒット70%では、DeepSeek V4 Flash の実効入力料金はおよそ $0.044/M に、Flash Lite はおよそ $0.093/M に下がる:
| モデル | 実効入力 (70% キャッシュ) | 出力 | 月間合計 |
|---|---|---|---|
| DeepSeek V4 Flash | $3.08 | $8.40 | $11.48 |
| Gemini 3.1 Flash Lite | $6.48 | $45.00 | $51.48 |
これで4.5倍の差になる。エージェントループのシステムプロンプトが安定していて、実際にキャッシュ割引を引き出せるなら、DeepSeek V4 Flash は Flash Lite の価格帯よりも無料に近い。合計の差が広いままなのは出力の倍率のせいだ。Flash Lite には出力側にキャッシュのレバーがないからである。
安いモデルがひそかに負ける場面
トークン単価の計算は第1層だ。第2層は消費される総トークン数で、これはモデルがタスクを完了するのに何回試行が必要かに依存する。
ツール呼び出しの信頼性。 Gemini 3.1 Flash Lite は BFCL v3 で76.5%に達し(Google DeepMind model card)、本番運用の目安となるおおよそ70%のラインを余裕で上回る。DeepSeek V4 Flash は MMLU Pro で86.2、SWE-bench Verified で79を記録するが(DeepSeek V4 Flash model card)、Terminal Bench 2.0 のマルチステップのツールトレースでは V4 Pro と比べて測定可能なほど性能が落ちる。コミュニティのテストを通じて見えてくるパターンは一貫している。Flash は4〜6段のツール呼び出しチェーンを綺麗にこなし、8段を超えるとエラーが積み重なり始める。Flash Lite は同じトレース深度でより長く持ちこたえる。
Time to first token。 ループのなかでは Flash Lite の方が速いモデルだ。Google が公表している数字は Gemini 2.5 Flash と比べて Time to First Answer Token が2.5倍速く、出力速度が45%向上している。Artificial Analysis は Google の API で1秒あたりおよそ347の出力トークンを計測している。DeepSeek V4 Flash は比較できるスペックを公表していないが、最近のエージェントベンチマークのスレッドに出回るフィールドレポートでは、標準プロバイダー上で150〜200 tok/s の帯域とされている。人間がレスポンスを待っているインタラクティブなコーディングエージェントでは、この差は体感される。夜間のバッチ実行では、目に見えない。
なじみのないツールスキーマ。 Gemini が Google 自身のツール利用トレースで学習していることが、なじみのない関数シグネチャに対する Flash Lite の優位になる。ベンチマークで見たことのないツールでも、一発でスキーマを正しく辿る傾向がある。DeepSeek V4 Flash は標準的な JSON-Schema の関数呼び出しでは優秀だが、ツールが不正な形式のレスポンスを返したときの回復がやや苦手だ。エージェントが独自スキーマを持つロングテールな社内ツールを使うなら、この差は効いてくる。
出力の簡潔さの規律。 Flash Lite はデフォルトでより引き締まった出力をする。シニアエンジニアがコードレビューのコメントに書くものに近い。DeepSeek V4 Flash はコードブロックの周りに説明的な散文を加える傾向があり、ドキュメントには良いが、消費側が人間ではなく別の LLM であるエージェントループではトークン請求を膨らませる。プロンプトで回避できるが、それは摩擦だ。
ここでのポイントは、一方のモデルが優れているということではない。見出しの価格差は、リトライ率とトークンの冗長さを勘定に入れると縮むということだ。Flash Lite が1.0回で完了するタスクを DeepSeek が平均1.4回必要とするなら、実効コスト比は3.4倍からおよそ2.4倍に縮む。2.0回必要なら、差は実質なくなる。
判断ルール
数週間にわたって混在したエージェントワークロードで両モデルを走らせた末に、書き留めておきたいルールはこうだ:
DeepSeek V4 Flash を選ぶとき:
- ループが範囲限定(ツール呼び出し4〜6回、1〜2ファイルに収まる)
- システムプロンプトが安定していて、ダッシュボードからキャッシュヒット率60%以上を確認できる
- タスクあたりの出力量が多い(長いコード生成、複数ファイル出力、構造化レポート)
- コストが制約条件で、失敗は別の経路に回せる
Gemini 3.1 Flash Lite を選ぶとき:
- ループがツール呼び出しを6〜12回連鎖させる、またはなじみのないツールスキーマを含む
- インタラクティブなレイテンシが重要(開発者向け IDE エージェント、チャット型コパイロット)
- 出力が短く構造化されている(JSON レスポンス、ツール呼び出し、簡潔な要約)
- キャッシュヒット率をまだプロファイルしておらず、楽観的な前提で予算を組みたくない
混在ワークロードを走らせているなら両方をルーティングする。前段にクラシファイアを配線し(または ofox の統合エンドポイントを使ってモデル名だけで切り替え、SDK コードに触れずに済ませる)、範囲限定のタスクは DeepSeek へ、マルチステップやスキーマ重めのタスクは Flash Lite へ振り分ける。ルーティングのロジックはどちらのモデル選択よりも価値がある。これは ハイブリッドルーティングパターンガイド と、より広い エージェントのモデル選定の解説 で扱っている。
「予算重視のエージェントループ」が実際に意味するもの
用語についての注記だ。マーケティングのコピーでは「予算重視」が引き伸ばされるからだ。「予算重視のエージェントループ」と呼ばれるワークロードには3つの形がある:
- 高頻度・低リスク — チャットのトリアージ、インテント分類、半構造化ドキュメントからのデータ抽出。両モデルともここでは大幅にオーバースペックだ。どちらかに課金する前に 無料ティアの選択肢 を検討してもいい。
- スケールする範囲限定のコーディングタスク — 自動テスト生成、スキャフォールディング、単一ファイルのリファクタリング。DeepSeek V4 Flash がコストで勝ち、品質は十分に近いのでルーティングの問題はめったに出てこない。
- マルチステップのリサーチや計画 — 10件のドキュメントを読み、統合し、計画を出力する。Flash Lite のツール呼び出しの信頼性がプレミアムを正当化するのはここで、とくになじみのないツールに当たる場合だ。
あなたの「大量のエージェントループ」が実はカテゴリ1か2を意味するなら、答えは DeepSeek だ。チェーンの長いカテゴリ3を意味するなら、Flash Lite の信頼性がひそかに効いてくる。
1つのエンドポイントで両方を走らせる方法
ofox で動かしているなら、両モデルとも同じ OpenAI 互換エンドポイントを通じて公開されている。モデル名を入れ替え、それ以外のリクエストの形はそのまま同じにする:
from openai import OpenAI
client = OpenAI(api_key=OFOX_KEY, base_url="https://api.ofox.ai/v1")
resp = client.chat.completions.create(
model="deepseek-v4-flash", # or "google/gemini-3.1-flash-lite-preview"
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_msg}],
tools=TOOL_SCHEMA,
)デプロイ前に ofox カタログで正確なモデル ID を確認すること。Google が Flash Lite を preview から GA へ昇格させるにつれて、preview のモデル名は変わることがある。1つのキーで複数モデルにディスパッチする全体像については、集約ゲートウェイの概要 を参照してほしい。
結論
DeepSeek V4 Flash はこのテーブルで安い API であり、キャッシュヒットが効き始めれば月間支出の合計は4〜5倍の範囲にとどまる。Flash Lite のテキストキャッシュは入力側の差を縮めるが、出力の倍率が合計を広いままに保つ。範囲限定のコーディングエージェントには、これがデフォルトの選択だ。Flash Lite は使わない能力に対して支払うことになる。マルチステップのツールループ、スキーマ重めのワークフロー、トークン単価よりリトライ率の方が効いてくるあらゆる場面では、Gemini 3.1 Flash Lite の信頼性がプレミアムに値する。最も安いモデルは、タスクを一発で完了させるモデルのことだ — そして予算重視のエージェントループにとって、それはワークロード固有の答えであって、普遍的な答えではない。
より広い DeepSeek ファミリーの価格の文脈については、DeepSeek API 価格の分解 を参照。Gemini の上位ティアについては、Gemini 3.1 Pro 詳説 が Flash Lite に対するトレードオフ空間を扱っている。ベンダー横断のより広いランドスケープは、Claude vs GPT vs Gemini モデル比較 と LLM API 選定の意思決定マトリクス にある。