
Claude Code Token Optimization 2026: 5 Strategies That Cut Your API Bill by 60-90%
Five Claude Code optimization techniques that actually move the needle: cache TTL discipline, /compact and /clear, Sonnet-default routing, isolated subagents, and trimming MCP tool bloat.
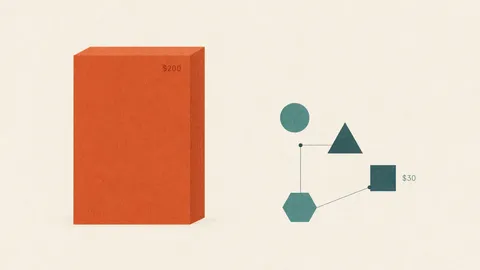
$30/Month AI Coding Stack vs $200 Subscriptions (2026)
Stop paying for throttled AI access. This guide breaks down a $30/month stack using open-source CLIs, API gateway, and tiered model routing to match $200 subscription workflows.

AI Coding Agents Compared 2026: Claude Code vs Codex CLI vs Cursor vs DeepSeek TUI
Four serious coding agents, four philosophies. We compare Claude Code, Codex CLI, Cursor, and DeepSeek TUI on price, quality, daily-driver feel, and where each one breaks. Picked one already? Skip to the use-case matrix.
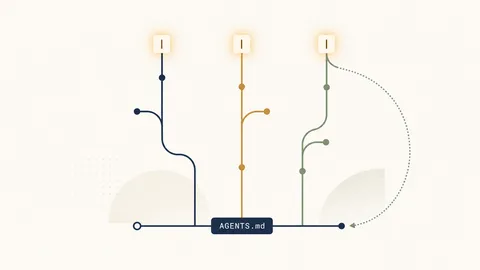
Codex CLI Workflow: The Setup Senior Devs Use in 2026
The real Codex CLI loop — AGENTS.md, plan mode, worktrees, GPT-5.5 vs GPT-5.4 Mini trade-offs, and the seven mistakes that waste your first week.

Qwen 3.6 Plus API: Complete Guide to Pricing, Benchmarks, and Access (2026)
Alibaba shipped Qwen 3.6 Plus on April 2, 2026 with a 1M-token context, an SWE-bench Verified score within two points of Claude Opus 4.6, and pricing that undercuts Opus by ~30×. Here is what is actually true after a month of production use — pricing, benchmark deltas, model ID, and a working code path through ofox.ai.

Best LLM for Coding by Task in 2026: Decision Matrix
Claude Opus 4.6, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4 Flash ranked across 10 coding sub-tasks. One model per row, May 2026 pricing, plus a 5-question self-assessment.
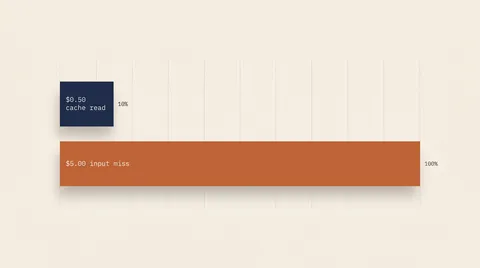
LLM API Cache Hit Math: Why Your DeepSeek Bill Says $4 But the Pricing Says $50
The official DeepSeek V4 Flash price is $0.14 per million input tokens. The bill on a real coding workload is closer to $0.005. The 28x gap is cache hit math, and almost nobody calculates it correctly. Here is the worked math across DeepSeek, Claude, and OpenAI in 2026.

Claude Opus 4.6 vs GPT-5.5 vs Gemini 3.1 Pro: Reasoning Benchmarks (3 Real Tasks Tested)
Three reasoning tasks, three frontier models, one weekend of side-by-side runs. Opus 4.6 still leads on careful step-by-step logic, GPT-5.5 wins on speed-of-correct-answer, and Gemini 3.1 Pro delivers ~70% of the quality at one-third the price. Here is the breakdown — including why we tested 4.6 instead of 4.7.
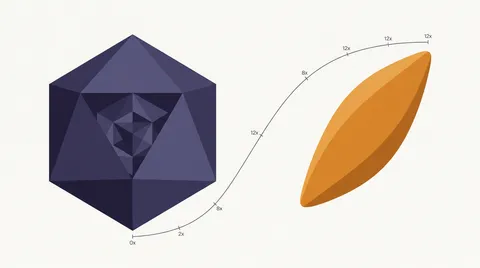
DeepSeek V4 Pro vs Flash: Real Cost-Quality Tradeoff
V4 Flash is 12x cheaper than V4 Pro and nearly equal on bounded coding tasks. Learn which 3 task types expose the gap and how to cut your bill 80% by routing smartly.
Claude Code Backend Switching Guide (2026): DeepSeek, OpenRouter & More
Route Claude Code through DeepSeek, OpenAI, or OpenRouter by changing two env variables. Covers 4 backend configs, shell aliases, and pitfalls that break tool calls.